How Capital One innovates using “You Build, Your Data”
Presented at Snowflake Data Cloud Summit 2024 by Jim Lebonitte, Sr. Distinguished Engineer at Capital One.
With data at the core of many business decisions and advances today, including AI-driven capabilities, companies must develop strong, data-driven cultures to move forward. At Capital One, we’ve been on a decade-long data journey that has led to reimagining our entire data ecosystem on the cloud. Key to our progress was enabling users to manage their own data by embedding centralized data standards and governance in unified, self-service data platforms.
At Snowflake Data Cloud Summit, we shared how we built our platform with a “You Build, Your Data” approach that equipped our various data stakeholders with self-service capabilities to use and build data applications. We will discuss the features of our data platform and share best practices for companies as they consider building their own data platforms.
“You build, your data” approach
In moving to the cloud, Capital One modernized its data ecosystem, including adopting Snowflake at scale. During this journey, we realized we needed a way to empower our data users to move quickly at scale while remaining well-governed.
We adopted a “You Build, Your Data” approach to give our data users greater ownership and accountability over their data. Similar to the concept of “you build it, you own it” in software development, the mindset equips our data engineering talent to meet the demands of the business while keeping in place standard ways to solve our problems and adherence to governance and policy commitments.
The two concepts that allowed Capital One to implement the “You Build, Your Data” mindset were the following:
-
Unified, self-service platforms: The “You Build, Your data” approach is made possible with a common, self-service data platform to empower users and give them autonomy.
-
Governance and standards: At the same time, we provided the right guardrails for maintaining a well-managed data ecosystem and following data governance policies.
Combining these two concepts empowered our data users to build applications with tech teams while adhering to centralized data management policies.
Achieving scale with a unified, self-service data platforms
We found unified platforms are the best ways to scale and standardize data management. To meet the needs of our internal customers, we heavily focused on providing a unified experience layer or self-service portal that supports data publishers, consumers, risk managers and business owners. Additionally in our platform, a suite of runtime capabilities span orchestration layers, data publishing, data consumption, data governance and infrastructure management.
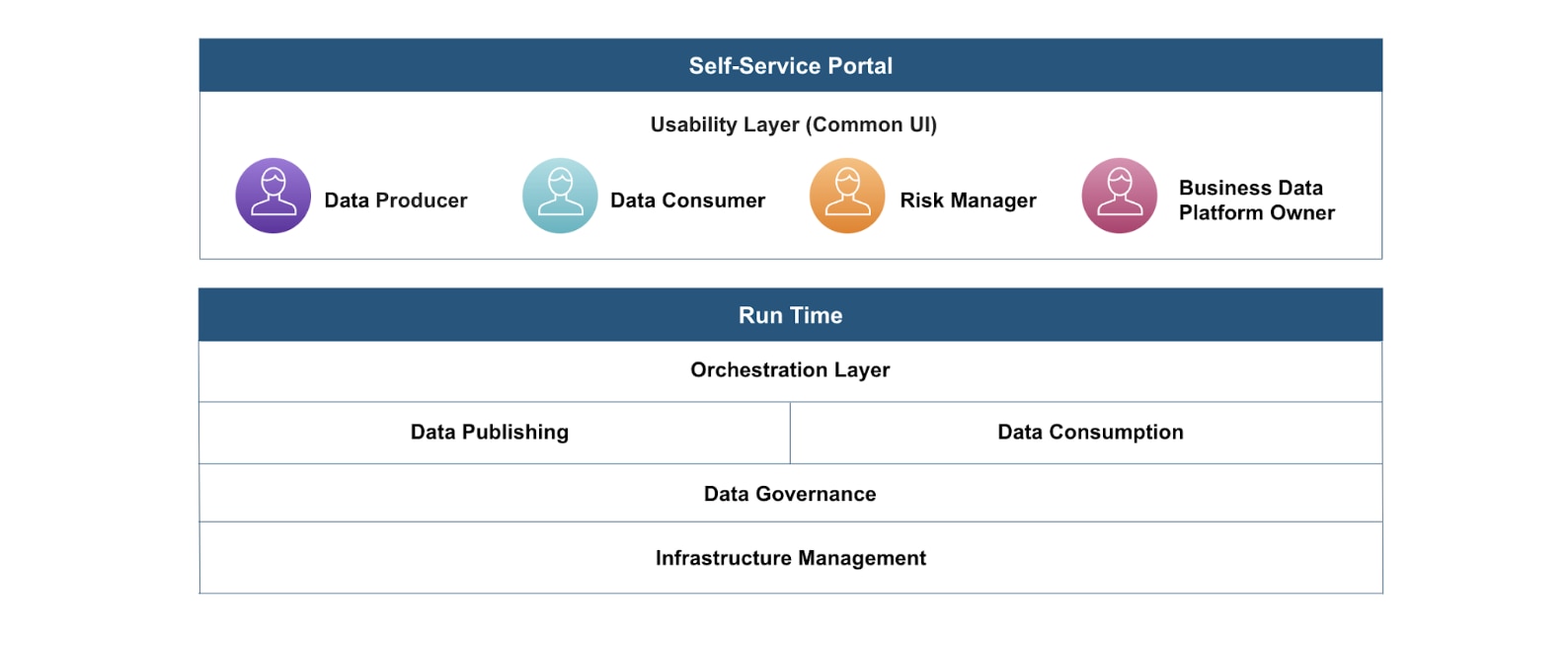
This data platform allows our line of business engineering, data science and data analytics teams to focus on building applications that support their business requirements without worrying about infrastructure, data governance and resiliency. The platform we built includes the following capabilities:
-
Self-service portal features: The portal offers various experiences depending on what you are trying to accomplish such as data modeling, pipeline designing and access approvals.
-
Runtime features: At runtime, the information entered into the portal deploys automatically to the runtime environment. The automation handles executing tasks on the data such as provisioning storage locations, central and federated pipelines, operational catalogs and tokenization.
These self-service platforms provide a broad set of capabilities that ultimately enable data users to build data solutions that power our business.
How it works: the experience of a data producer
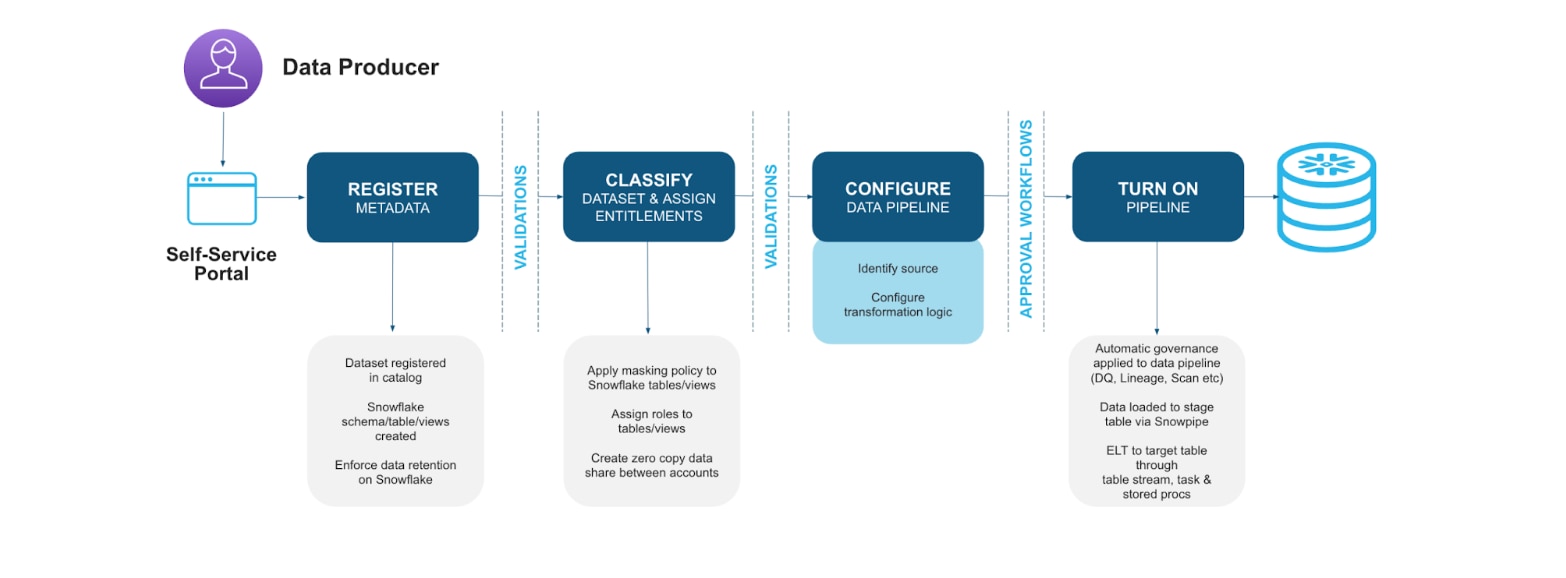
Our self-service portal is the front door to data at Capital One. For example, a data producer that wants to create a new dataset goes through a series of steps and approvals in the self-service portal. They include:
Step 1 - Register: The first step is metadata registration to register all the columns of the data set in the catalog. Also in this step, we have built in adherence to our global data model as producing teams create more data.
Step 2 - Classify: Next, we classify the dataset with the characteristics that help assign the right people to the approver roles when users request access for data.
Step 3 - Configure: We configure the data pipeline around the transformation logic, meaning how the data is going to make its way to the final destination data store.
Step 4 - Pipeline On: Once all the previous steps are completed, data set owners approve the creation of the dataset and pipeline in production. At this point, the deployment automation kicks in.
Automating our runtime tasks
Once approvals are complete, a series of steps in the runtime environment automatically deploy our configured assets into Amazon Web Services. These tasks for data processing and analytics ensure efficient and well-managed execution of our data pipelines.
The automation steps handle:
-
Creating the data set entry in our business metadata catalog
-
Provisioning the destination data store location
-
Provisioning the data pipeline configuration that handles the routing of data to the right location
-
Initializing control plane services, such as data lineage and data quality management, with dataset information to ensure the right destination matches the right assets
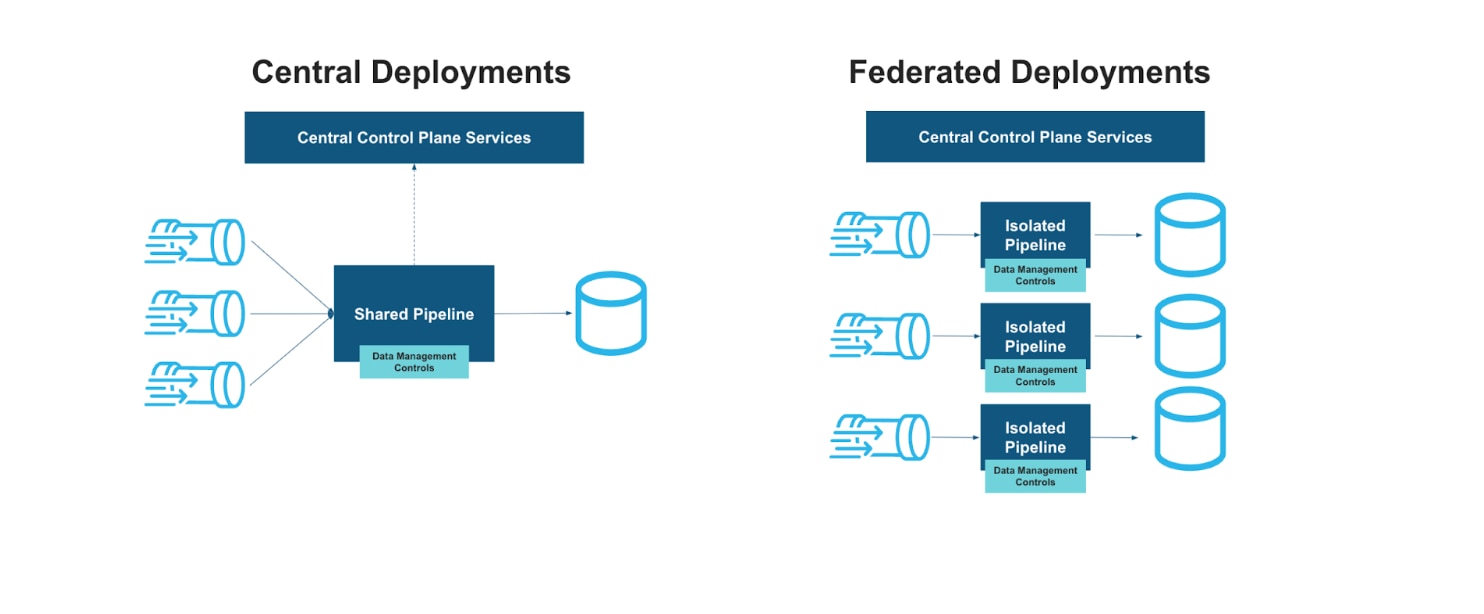
Central and federated deployments
We realized we needed a variety of experiences and architectures that support our different users and use cases.
Most of our initial core ingestion and transformations flow into a shared pipeline that follows a central deployment model. The advantage of the shared pipeline is it enables business applications built by software engineer personas to stream data into our data lake in real time without requiring deep data engineering technical knowledge or intervention. In this model, enterprise data platforms manage a central architecture component, while at the same time, users still build and own their pipelines through the configurable self-service portal.
While the central deployment model was successful for software engineers, we realized it was too rigid for our other persona, the data engineer. There was a need for our data engineers to have the flexibility to configure their own infrastructure and write their own custom code. In other words, we required a deployment model tailored to different user needs. Our federated deployment model provides for customization by enabling our engineers to write their own code without obstacles or dependencies on other teams. We partnered with our CI/CD platform team to build a solution in which the platform is built into the deployment scripts and takes advantage of serverless infrastructure runtimes. The deployment process uses our CI/CD tooling and gives our engineers the flexibility of using Apache Spark SDK. As a result, we have experienced high adoption of the federated deployment model by our engineers.
Access controls
Lastly, our self-service portal metadata enables automatic deployment of the Snowflake assets required for a user to access their data at design time. These include access roles along with table and view definitions. Once these assets are deployed, consumers can immediately request access through our identity platforms. Data producers approve the requests from data consumers, removing the need for intervention by central platform teams.
Key takeaways
As a data-driven company, Capital One requires massive scale from its data platforms. In our journey to empower our data users while achieving speed and scale across the business, we took away the following best practices for building data platforms:
-
Enable a self-service portal and runtime experience
-
Provide deployment models tailored to users
-
Automate everything from design time to runtime
Through a “You Build, Your Data” approach, we are able to help our associates innovate through custom self-service capabilities to use and build data applications according to each stakeholder’s needs. Unified, self-service platforms are key to a well-managed, scalable data ecosystem.


