How to deploy CI/CD for Snowflake
Presented at Snowflake Data Cloud Summit 2024 by Yudhish Batra, Distinguished Engineer, Capital One Software, and Hiren Shah, Sr. Manager, Data Engineering, Capital One Software.
Modern software development is about speed and efficiency. The introduction of continuous integration and continuous delivery (CI/CD), an iterative practice of fast development and release that allows businesses to move quicker and refine products over time, has proven to be an important advancement in software build and delivery.
Growth in CI/CD has been focused on tools for application code. However, less mature is CI/CD for databases. Capital One Software used the techniques of CI/CD to create an automated solution for deploying code on Snowflake. At Snowflake Data Cloud Summit, we shared how we automated CI/CD on Snowflake and the benefits we gained moving away from manual processes. Let’s take a look at how businesses can successfully deploy CI/CD for databases.
What is CI/CD?
A CI/CD pipeline is the process of writing, testing and deploying code continuously. By automatically integrating code changes into a shared source code repository that gets updated in intervals, businesses benefit from faster release cycles while also reducing errors that can come from manual processes.
The pipeline includes two steps:
Continuous integration (CI): Developers build the code, working simultaneously to commit code to the shared repository and fix bugs in frequent iterations until the code completes initial testing.
Continuous delivery (CD): Picking up after initial testing, CD uses advanced testing and configurations to complete a build that meets the requirements for a production environment. Again through rapid iterations, developers identify and fix issues until the code is delivered for deployment.
What is database CI/CD?
Applied to databases, CI/CD is the process of managing database schema changes and application development. Database CI/CD helps development teams manage schema updates such as changes to table structures and relationships. Software updates to applications can also be executed quickly and continuously without disruption to database users.
The importance of CI/CD
The traditional process of software development, often called the waterfall method, follows a sequence of steps that could take from weeks to years to deliver a finished product into the market.
In contrast, a CI/CD pipeline provides companies with efficiency in developing software and the freedom to experiment and fail. Software that goes through a CI/CD process is often more stable, reliable and easier to maintain.
CI/CD works best for companies with mature developer programs as they must be committed to establishing and managing automation. CI/CD also requires careful planning and project management to ensure the generation and production of new builds through the pipeline while meeting important standards for quality.
Capital One Software employed a CI/CD approach in Snowflake to:
-
Build and host an application
-
Accelerate software development
-
Reduce developer cognitive load
-
Improve the quality of code
Now let’s take a look at how we deployed CI/CD in Snowflake for Capital One Slingshot.
Manual deployment in Snowflake
Slingshot, a data management solution from Capital One Software, helps companies maximize their Snowflake investment with granular cost insights to understand usage through multiple lenses, actionable recommendations to optimize resources and reduce waste, and streamlined workflows to more easily manage and scale.
Many of the core capabilities of Slingshot are built on top of Snowflake. Slingshot is deployed in multiple Snowflake accounts across regions and those accounts must be kept available at all times. The scale at which we deploy Slingshot within Snowflake, which includes 115+ accounts and 4,000+ tables, requires us to use CI/CD.
To manage data processing pipelines built for Slingshot, we first deployed it manually in Snowflake. Developers created the code and deployed it into the Snowflake account and also synced the code to the GitHub repository. When testing was complete, database administrators deployed the code into the higher environments.
In these manual processes, admins needed to depend on developers and vice versa. The main challenges we experienced included:
-
People dependencies: There were too many dependencies between the developers and admins, which slowed down the development and deployment processes.
-
Poor developer experience: The manual processes also led to a poor developer experience due to the slowdowns and scale.
-
Error prone: Manual deployment could also suffer from human error.
-
Environment sync issues: Different versions of tables could end up in different environments and lead to problems with syncing.
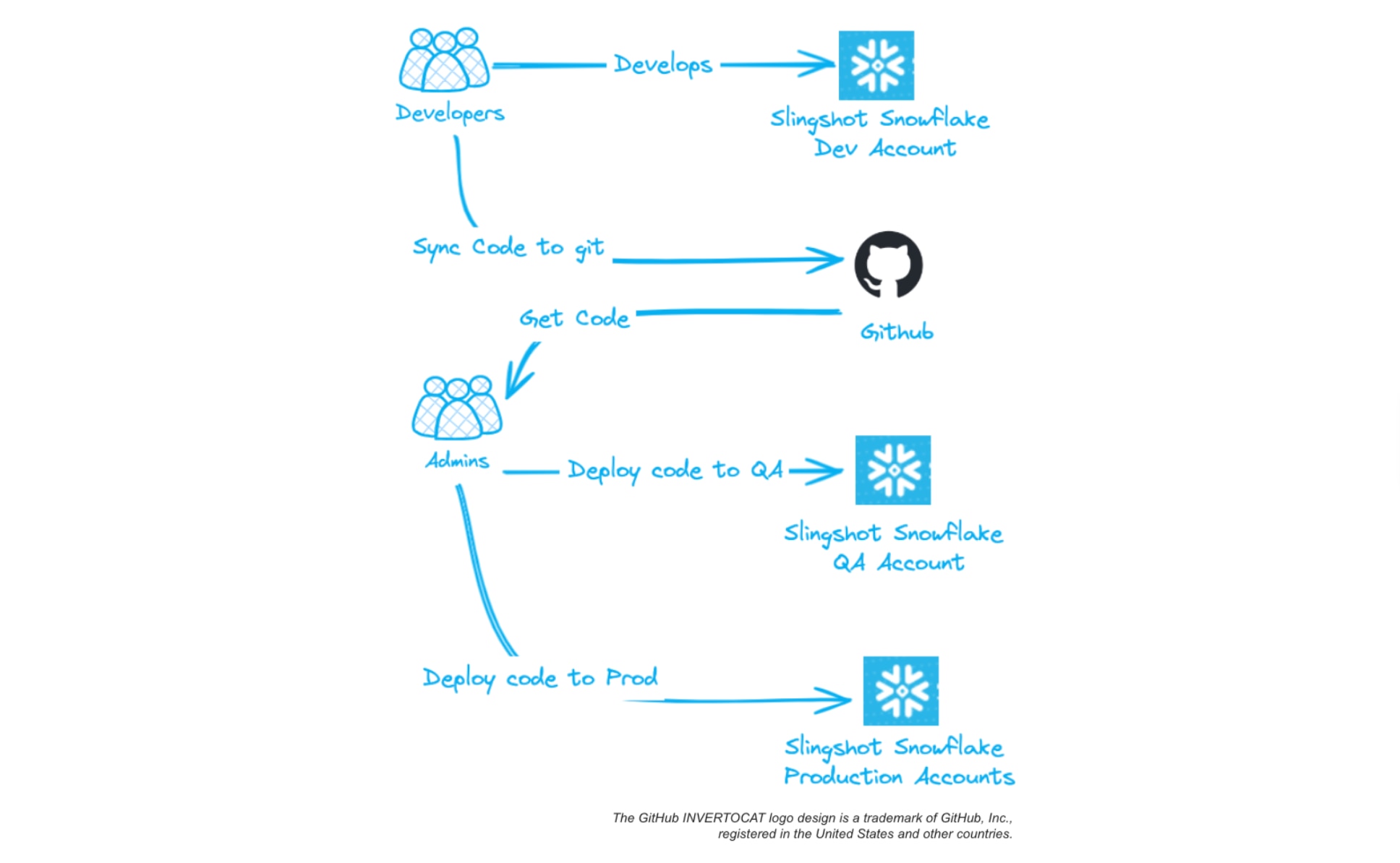
Automating CI/CD in Snowflake
We came up with an automated solution for maintaining Slingshot and making changes and updates to the application in Snowflake. Through a CI/CD pipeline, we hoped to integrate and deploy code for Slingshot faster with fewer dependencies and greater accuracy at the scale which Slingshot required.
At a high level, the CI/CD pipeline consists of developers writing code and deploying the code to the sandbox through the automated solution. Developers promote the code using open-source automation server Jenkins, storing the artifacts of the code to JFrog Artifactory. Through this pipeline, we remove the dependency of developers and admins to deploy the code to the Snowflake accounts. The solution also allows us to promote the code more quickly into the Snowflake environment.
The three main components of our solution included:
-
A customized open source library that we created by modifying the schema-based library developed by Snowflake.
-
A standardized Git structure for Snowflake objects to help us review the code quality and reduce the review time for developers.
-
A centralized pipeline for faster bug fixes and less dependencies between developers and admins.

Let’s take a closer look at each of these components.
Customized open source library
We built our solution using a schema change open source library developed by Snowflake. The library is a database change management tool for managing Snowflake objects. This was a good starting point for us with the following open source features:
-
Naming standardization for SQL scripts based on type of objects (i.e., versioned, repeatable or always)
-
Script execution history captured in Snowflake tables
-
Checks on duplicate script names
-
Parameterized code using Jinja templates
We further customized the library to meet our needs. Our modifications included:
-
Object level versioning, which goes a step further than the default script level versioning
-
Custom script execution order based on Snowflake object types
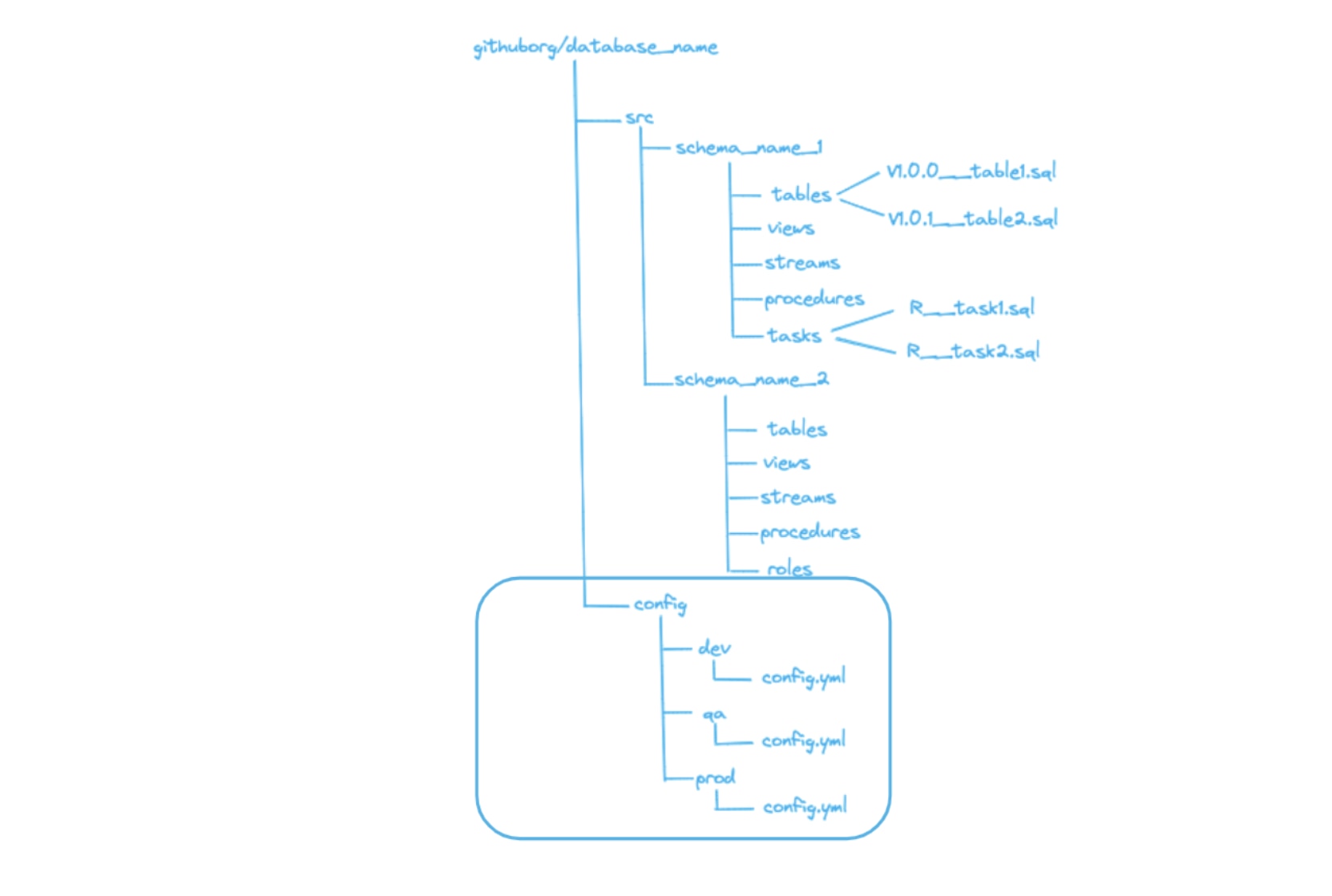
Standardized Git structure
We use GitHub to store, manage and control the different versions of our code. We standardized the Git structure for our code for improved quality, reduction in review time and easier maintenance of the codebase. These standardizations included:
-
Environment configurations: We set up different configurations per environment (e.g., dev, prod, QA) so that teams could manage their own pipelines in each environment, including required changes for database objects.
-
Object level versioning: We have the data version of the object with the versioned objects, stored procedures and functions with the repeatable objects and access-related versions in the always objects.
-
Flexibility in management and standardization: We also gave developers the flexibility to use the folder structure in the customized library based on the use case for placing Snowflake objects in GitHub. Developers no longer have to worry about following a hardcoded structure as long as they are following the right pattern from script versioning.
Centralized pipeline
The last piece of our automated solution was our centralized pipeline, which allowed us to streamline the process of delivering changes to the Snowflake environment. Here are the features we put in place for our pipeline:
-
Reusable: Through the centralized pipeline, we’re reusing the code we deploy in the lower environments in the higher environments. This allows us to run the correct testing and deploy quality code into the production environment.
-
Multi-account deployment: We’re managing more than 115 accounts in Slingshot. Instead of creating a build for each account, we implemented one build with multiple account deployments. The developer creates one build and deploys across all accounts.
-
Standardization of changes: All changes are defined within the standardized GitHub structure. In this way, we avoid different versions in different environments. Only the correct or latest version will make its way to the production environment.
-
Governance controls: We allow developers to deploy through the lower environments without any change orders, but we have governance in place in the production environment. Developers must work with a change control tool to provide required details for governance.
Benefits of automating CI/CD
In creating our solution for automated deployments in Snowflake, we realized value in multiple ways such as improving the developer experience and reducing manual errors. The advantages over the older manual processes include:
-
No human intervention: Deploying to multiple Snowflake accounts without human involvement.
-
Change management benefits: Reduced numbers of hours spent on change management.
-
Developer productivity increases: Improved developer productivity through multiple deployments per day.
-
Quick rollback: Enabled quick rollback with audit tracking of changes.
Deploying CI/CD in databases
Although CI/CD processes have matured considerably over the years, applying the practice to databases can be complex and challenging. We hope sharing our solution provides businesses with a place to get started and some guidelines to follow. Putting in place an automated, centralized pipeline for Snowflake deployments can help data teams gain greater efficiency, speed and productivity while minimizing human error.


