Using Iceberg Tables to implement a lakehouse architecture
Presented at Snowflake Data Cloud Summit 2024 by Temesgen Meheret, Director, Software Engineering at Capital One and Christa (CJ) Jacob, Sr. Sales Engineer at Snowflake.
As data management practices evolve, a model for combining a data warehouse and data lake into one architecture has emerged with the data lakehouse. As companies advance in their use of data, such as with investments in AI and ML, the need for a lakehouse—which can reduce cost of ownership and accelerate AI adoption while maintaining high performance—is increasing.
We presented at Snowflake Data Cloud Summit on how we used Iceberg Tables to implement a data lakehouse architecture. In this article, we will describe how we came to build a data lakehouse in Snowflake and best practices we learned to help other companies interested in doing the same.
Why a data lakehouse?
Before the emergence of the data lakehouse, many companies first focused on data warehouses, which brought together an organization’s structured, relational data into a single repository for analytics and reporting. With the exponential growth in data, particularly unstructured data, data lakes emerged as a way to store massive amounts of raw unstructured and semi-structured data in a lower cost storage. This way, data teams were able to expose data as soon as they got it. Data analysts and data scientists could define the schema as they start reading it (schema on-read) in order to run advanced analytics or train machine learning models.
Emergence of a two-tier architecture: Data warehouse and data lake
However, there was still a need for a data warehouse to structure and analyze data in a performant manner using data analysts' preferred language of SQL, while maintaining transactional consistency for data changes and simplifying data governance and security. There was also a need for unique capabilities such as easily querying older snapshots of the data or cloning tables without copying the data. This led to companies, including Capital One, adopting a data architecture made up of both a data lake and data warehouse to store and process their data. Today, they are often used together to provide companies with the benefits from both types of data repositories.
The advantages of a data lake include:
-
Low-cost object store
-
Support for advanced analytics, including those involving unstructured data, data science and machine learning
-
Schema on read, which leads to easier and faster onboarding of data and enablement of AI/ML capabilities
The advantages of a data warehouse include:
-
Ease of use
-
Improved governance
-
Better discovery
-
Stronger SQL performance
-
ACID (atomicity, consistency, isolation and durability)
-
Zero-copy cloning
-
Time travel
In this two-tier architecture, companies use the data lake as the central repository for all types of data for data scientists, engineers and advanced analysts, while maintaining a separate copy of data in a data warehouse for business intelligence and analytics.

But the dual architecture also presents challenges for data management including:
-
High total cost of ownership: Maintaining two distinct systems can mean high costs associated with greater complexity and manpower.
-
Data staleness: There may be delays in data updates between the data lake and data warehouse.
-
Reliability: Multiple processes to ingest data introduce additional ETL steps that can increase the points of failure.
-
Drift: Discrepancies and inconsistencies arise with data changes in one system that are not reflected in another.
-
Vendor lock-in: Data warehouses often only support proprietary storage formats and migrating between platforms comes at a high cost to the organization.
Advantages of the data lakehouse
A data lakehouse architecture seeks to address these challenges. A data lakehouse combines the capabilities of a data lake and data warehouse into a single architecture. Businesses can still ingest data from a big repository of raw data into data lake storage while enabling the structured data and transaction management features typically found in data warehouses.
The key to making a data lakehouse work for all data users is the open table format, which uses a metadata layer on top of each data file that allows users to query data directly from the data lake – whether the data is structured, semi-structured or unstructured. Through this layer, users can implement predefined schemas, caching, indexing and make data discoverable in catalogs as tables for faster querying, similar to a data warehouse. The metadata layer is accomplished through an open metadata table format—Delta Lake and Apache Iceberg in the case of Capital One—that sits on top of the data lake’s open file format (Apache Parquet).
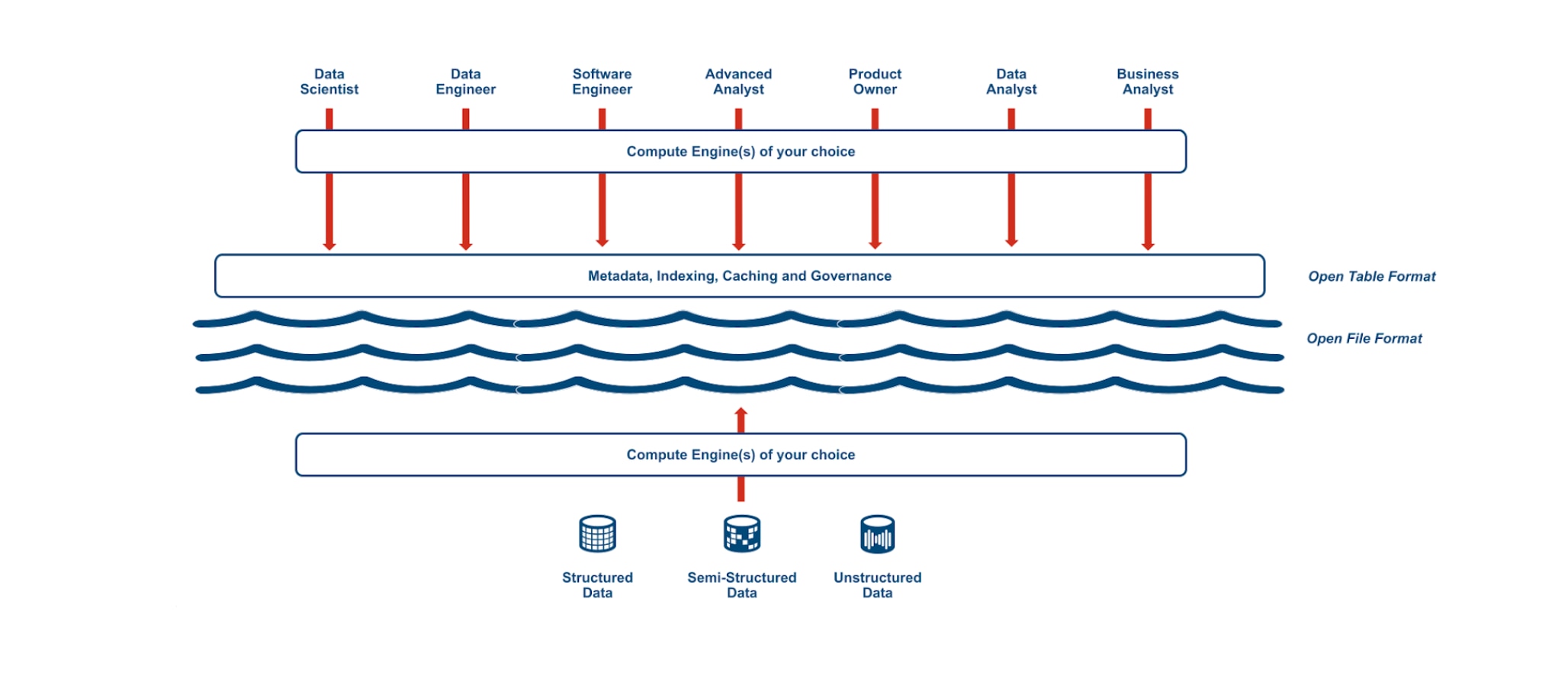
A data lakehouse resolves many of the issues found in the two-tier architecture, such as data redundancies and discrepancies, through a single system that captures all types of data in a low-cost store while employing data management features for governance, organization and exploration.
Pointing all consumption to a single place: SQL on Lake
All of our data users at Capital One, from data scientists and engineers to product owners and business analysts using SQL, query the same data exposed through the same table format. Duplicative data is less of a challenge with a data lakehouse. Total cost of ownership is also less expensive as your business no longer manages two systems and the integration of data from new sources is automated and open. Because of centralized storage leveraging open standard formats, it also opens up an array of opportunities for bringing on specialized compute engines of your choice and minimizing vendor lock-in.
Now let’s take a look at how Capital One used Apache Iceberg to implement a lakehouse architecture on Snowflake.
Implementing a lakehouse architecture using Iceberg Tables
Companies that want to leverage the benefits of a lakehouse architecture on Snowflake can use Iceberg Tables to accomplish this. In the past, querying data in Snowflake often meant copying files from cloud object storage into native Snowflake tables. Iceberg Tables is a table type in Snowflake that provides companies with a way to read and write data from their own external storage, such as a data lake, while enjoying the querying capabilities of Snowflake and the functionality of native Snowflake tables. Put simply, companies can store their data in a lakehouse architecture with consumption pointed to it, avoiding the costs of loading and storing data separately.
Snowflake’s Iceberg Tables rely on an architecture that uses the open table format Apache Iceberg as the table format and Apache Parquet as the data file format to store and process large datasets from a data lake.
What is Apache Iceberg?
Open table formats are key to bringing the features associated with a data warehouse to a data lakehouse architecture. Apache Iceberg is an open table format used by Snowflake for the efficient querying of large datasets in data lakes with SQL support. A table format specifies how data files are organized and accessed within a table.

A key benefit of Apache Iceberg is that it brings capabilities traditionally reserved for data warehousing such as data management and the structuring of data to data lakes and big data. These include defining a schema for data organization, querying using SQL, cloning of tables and time travel. Apache Iceberg also provides the flexibility and interoperability that comes with being an open source project, integrating with open data formats like Parquet for storing data and allowing different tools across vendors and platforms to access the data.
At Capital One, we use a storage layer with data files stored as Parquet. In our metadata layer, we leverage both Delta Lake and Apache Iceberg table formats. Iceberg captures table metadata in the form of metadata files, manifest lists and metadata files. The metadata layer consists of manifest files that Apache Iceberg creates to track the list of files that are part of a single snapshot, called metadata files. As different snapshots of data are created, there are references to the old snapshot, which allows for the capabilities usually associated with a data warehouse such as time travel.
Implementing lakehouse architecture with Apache Iceberg
With Snowflake’s support for Iceberg Tables, the storage engine supports writing data with Apache Iceberg metadata and provides access to data through Snowflake’s Iceberg catalog. At the same time, Snowflake’s query engine also supports reading Apache Iceberg data in the data lake for data managed by an external catalog. In these scenarios, both the data and metadata are stored within the customers chosen external storage locations.
At Capital One, Spark-based processes move data and metadata into our storage in the data lake. The data in the lake is in the Parquet file format and Iceberg table format, so the data is queryable from Snowflake. We use a catalog integration from Snowflake to the Iceberg catalog system of record that the pipeline also uses. Each time our pipeline creates new metadata, the catalog system records the latest location of the metadata, and provides that information to Snowflake to scan necessary files for queries. Data analysts can write the same queries they would normally write against Snowflake native tables, but now with Iceberg, Snowflake returns results after scanning files from our object storage.
At Capital One, we created a data lake pipeline that is Iceberg-aware, meaning we generate Iceberg metadata on top of our data. We use AWS Glue, which comes with native support for Iceberg tables, specifically for tracking Iceberg metadata. Additionally, we created a catalog integration between AWS Glue Data Catalog and Snowflake to make these tables accessible from Snowflake. Through our internally built data registration process, we make sure new data is registered in Glue and also in Snowflake as an Iceberg Table. At run time, our lakehouse architecture ensures that Snowflake leverages the latest metadata.
Optimizing Iceberg Tables for performance
A big concern in moving workloads from a data warehouse to the lake is a sudden slowdown in query performance, which in turn leads to higher costs. The same concern can apply here, but Iceberg Tables can be optimized to perform as close as possible to Snowflake native tables. The same optimizations that can be applied to Snowflake native tables can also be applied to Iceberg Tables.
-
Data layout optimizations: The way the storage engine lays out the data as it is being written will be critical to performance. These include the file size, row group size, number of partitions and compression method.
-
Indexes and statistics: Queries run faster if they can leverage indexes and statistics, which are collected in the metadata while writing the data, because they minimize the number of files to open or scan in order to locate the data.
-
Storage maintenance: Data stores require upkeep to make sure older, unused snapshots are continually cleaned up and files are compacted to the optimal size.
- Caching: Snowflake supports caching at multiple levels – virtual warehouse-level and the results-level. Performance optimization could also be implemented within the lake storage layer by precomputing the storage layout during ingestion.
- Row level update optimizations: The Iceberg spec supports two patterns for performing row-level updates; copy-on-write and merge-on-read. You can speed up workloads that are heavy on updates and deletes by choosing the merge-on-read pattern.
With optimization in these areas for data ingestion and query processes, a business can get close to native table performance using Iceberg Tables.
Maximize the value of your data with lakehouse architecture
Moving our data consumption to a lakehouse architecture on Snowflake with Iceberg has both improved flexibility to integrate various processing engines and reduced total cost of ownership. Open formats and Iceberg’s large ecosystem ensures longevity for our investments in data because we can easily plug in compute from any vendor, minimizing compute locking. The change in architecture eliminated duplicative storage costs and improved SQL performance on the data lake. We hope this article serves as a guide or example for companies looking to implement their own lakehouse architecture on Snowflake as a means to advance their data science and analytics capabilities.


