Optimizing queries for cost savings and better performance
Presented at Snowflake Data Cloud Summit 2024 by Ganesh Bharathan, Director, Customer Solutions Architecture, Capital One Software.
Inefficient queries can have a negative impact on a business. Bad queries strain database resources like CPU and memory, leading to bottlenecks and slower performance for internal teams. In a world that values speed, slow queries can also lead to poor customer experiences when they affect customer-facing applications, which can impact a company’s reputation.
Capital One is well-versed in how to optimize queries for cost savings and better performance in Snowflake. We presented at Snowflake Data Cloud Summit on lessons learned from our experience running an average of over 4 million queries a day in Snowflake. This blog covers the tips and tricks to tune queries, which can reduce cost and improve performance, resulting in maximum efficiency.
What is query tuning?
A query is a question or request for information from a database. As organizations mature and scale their data operations, requests naturally grow in size and complexity. But these queries, when not optimized for cost and performance, can unnecessarily burden existing systems and waste valuable time and resources.
That’s where query tuning comes in. Query tuning is the art of writing queries in a better way. The goal is to reach a query result while using the least amount of compute resources possible.
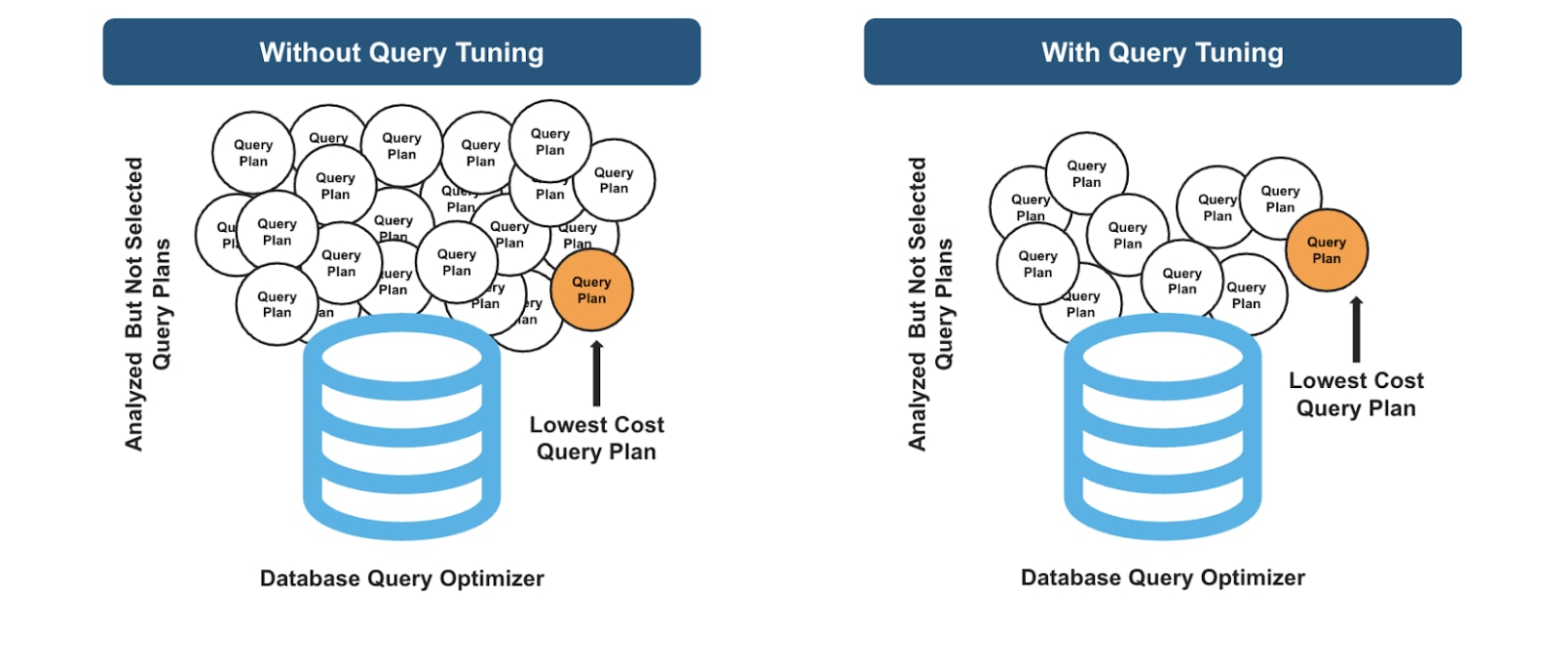
Poorly written queries also affect your systems’ query optimizer, which is supposed to present the most efficient way to execute a query by evaluating the possible query plans. But with only a few seconds to generate and evaluate as many plans as possible, a query optimizer with a bad query will produce many plans from which to choose the lowest cost plan to optimize your code. The idea is similar to going through a buffet table with a small plate in less than a minute. However, when a query has been tuned properly, the optimizer produces a fewer number of plans, which means less clutter from which to choose the lowest-cost plan for your query.
How to optimize queries
With years of experience optimizing queries at scale, we’ve learned important tips and tricks that any business can apply.
Avoid 6 common mistakes
At Capital One, we’ve educated users to avoid six common mistakes that can produce inefficient queries. The following are the most common mistakes to avoid:
-
Single row inserts: Use copy commands to load data rather than single row inserts, which slow down the load time. Single row inserts also negatively impact query performance as one must scan multiple files created by the single row inserts.
-
Aggregating more than 10 columns: Avoid aggregating a large number of columns at once, which is a practice that can severely impact performance. If you have aggregates on more than 10 columns, each time Snowflake tries to join data in the back end the platform must take these columns into account in its memory. This leads to a longer and more compute-intensive query. To avoid this users should try and aggregate 2-3 columns at a time and then complete the aggregation in the final step.
-
Cartesian product joins: Avoid Cartesian product joins, which joins every row from one table to every row of another table. Check your explain plans as in most cases the product join occurs from a typo in the join condition.
-
Deep nested views: Setting up a view to reference another view requires materializing each view at each stage, which is compute intensive and slows performance. Best practice is to break it down into temporary tables and have them referenced in the SQL query. This avoids the often costly and time-consuming scanning of large amounts of data from Amazon Simple Storage Service (S3).
-
Spilling to disk: Check the performance of large queries for disk spilling. Data spilling to disk means you are failing to use the optimal warehouse size or your query needs to be reduced in size. If spilling occurs, start adding filters or move the query to an appropriately sized warehouse.
-
Select * from a large table: Avoid the select * query for large tables as it can be very costly for columnar databases such as Snowflake. Make sure to pick the columns you actually need and add appropriate filters to reduce the amount of data.
Order queries for greater efficiency
Now that we’ve reviewed some of the things to avoid, let’s take a closer look at actions you should take for query tuning. The first thing to look at is the order in which you run the query.
For example, you may be wanting to access data from small, medium and large tables. If a user first joins the large table with a medium table, that is a costly join in terms of database performance as you’re dealing with results that can be quite large in size.
A better approach would be to first create a temporary table with the small table and medium table. Once this intermediate step is completed, you can move on to join the large table. In this order, the join with the biggest table happens only once, significantly reducing the amount of data scanned and leading to faster query execution. When writing your queries, always use your smaller tables to create internal temporary tables. We recommend being creative in the way you choose your joins because joining a small table to a big table tends to be a costly operation.

Reduce the amount of data scanned
An important step in getting to the most efficient queries for data retrieval is reducing the amount of data scanned. In other words, you want to shrink the portion of the database your system must examine to retrieve information for your query. Reducing the amount of data scanned can significantly decrease the amount of time and resources required to retrieve information and improve query performance.
In Snowflake, the query run time and cost are directly proportional to the amount of data scanned. Avoid running queries that scan large data sets to keep costs lower.
One best practice we learned was to never hardcode date ranges in your filter conditions such as “date greater than 2024-01-01.” While useful today, that date range will lead to your queries referencing the same range four or five years from now. We recommend using filters such as “current_date minus 30 to 60” depending on your reporting needs.
Be mindful of external checks
When working with individual rows of data in a query, pay careful attention to any external checks your query might be performing. These checks, which can greatly impact cost and performance, can include fetching data from external sources such as web APIs or assessing datasets from another table from external joins.
When building applications on Snowflake, the process of building data pipelines will involve checking for new data with existing data. We recommend you pay close attention to the following for optimized queries:
-
Merge commands: Merging large tables can quickly add up to significant costs. A good idea would be to break the table in partitions range and filter on the most recent data in your merge operations.
-
Union: Make sure to use “Union all” instead of “Union” to avoid costly data duplication checks.
-
Row-level policies: Avoid row-level policies in your queries, which lead to using costlier explain plans. These policies add complexity to the execution plan as the database must evaluate policies for each row in the set.
Improving query performance using Snowflake
In addition to the optimization steps we’ve discussed above, you can also take advantage of the options in Snowflake for improving your query performance. However, you need to pay close attention to user access patterns and determine which option best fits your use case. Let’s take a closer look at use cases that best fit the options for improving performance:
-
Data model can be the foundation for efficient queries. Investing time now into optimizing your data model for the best performance and logical table connections can reduce the need for query tuning later.
-
Search optimization is your best option if the queries are like looking for a needle in a haystack. Your users in this scenario are running queries that scan large tables only to get to a few records, leading to longer query times.
-
Auto clustering is a good option when users frequently query large tables by filtering on specific columns.
-
Materialized view can help if most users perform aggregation on a single table multiple times in a day and the data in the table is not volatile. Materialized view in Snowflake precomputes the results of a query and stores them as a separate table. For matching queries, Snowflake retrieves information from this precomputed table rather than executing the query each time, which reduces response times and processing load.
Load jobs in Snowflake
Another important factor to consider when optimizing your queries in Snowflake is the cost of load jobs. Data load jobs play an instrumental role in data management and keeping your databases updated. However, they can quickly add up in costs. Here are a few tips for decreasing the load time and decreasing costs:
-
Break your files into smaller files, for example in multiples of 16, and load them in parallel, which will speed up load times.
-
Right-size your warehouses. You may be surprised at the number of loads you can run on a small warehouse.
-
Reduce your auto suspend time to one minute since load jobs do not rely on caching and terminating idle sessions will not impact performance.
Taking these steps will help ensure that your teams are efficiently managing your database resources when it comes to load jobs in Snowflake.
Optimizing queries with Capital One Slingshot
To practice these tips for query optimization on a day-to-day we’ve learned the following steps are helpful:
-
Acknowledge that workloads and user behavior change constantly.
-
Track waste in your environment obsessively.
-
Get alerts and recommendations for remediation.
Capital One has more than 50 petabytes in Snowflake and over 8,000 users are able to run queries at scale. This kind of scale requires tooling to effectively optimize queries. We developed Capital One Slingshot to help us optimize our own cost and performance so that we could focus on maximizing the value of our data for the business.
Slingshot enables businesses to maximize their Snowflake investment with granular cost insights to understand Snowflake usage through multiple lenses, actionable recommendations to optimize resources and reduce waste, and streamlined workflows to more easily manage and scale Snowflake.
This includes Query Advisor, which helps users level up query writing instantly with detection of inefficient query text, saving on costs or time by reducing ineffective query patterns. Warehouse recommendations also help users optimize under- or over-utilized warehouses with schedule recommendations, to ensure they are meeting cost and performance needs. Users can also set data warehousing sizing schedules to right size warehouses, increasing spend efficiency and reducing data spillage.
If you’d like to learn more about how Slingshot can help you maximize your Snowflake investment with tools like Query Advisor, request a personalized demo with our team today.


