How to tackle the problem of an unmanaged data sandbox
Presented at Snowflake Summit 2022 by Nagender Gurram, Senior Director of Software Engineering, and Yudhish Batra, Director of Software Engineering, for Capital One Software.
Today, the analyst community runs a lot of ad hoc workloads in the Snowflake data cloud without much governance, data management controls, or an easy way of moving these workloads to well managed data processing pipelines. Oftentimes many critical dependencies are created on this ad hoc process, which can lead to problems, including the lack of metadata, reduced data quality, no change management process, and a lack of monitoring and well defined incident management processes.
Over the past several years, Capital One solved the problem of unmanaged data sandbox by building a self-service platform using Snowflake core capabilities.
We recently shared more about how we tackled this problem at the 2022 Snowflake Summit, and wanted to share more about our learnings here. Keep reading for key features of our platform, and how it has helped business users focus on the core business functionality and not worry about building the processes and controls.
What is a data sandbox?
Before we get into how we solved the problem of an unmanaged data sandbox, let’s discuss what a data sandbox actually is.
A data sandbox is a collaborative environment where data analysts and data scientists can analyze and store data. It encompassess both personal and collaboration spaces, and provides a playground environment for building and testing new processes and models on new production data. We use Snowflake Schemes to separate our sandbox data so that it won’t impact production spaces.
Below are some of the key benefits of a data sandbox.
- Reusability: Users can reuse the data and processes than building it from scratch.
- Data Protection: A sandbox provides a secured and controlled environment for analyzing and storing data. This avoids exposing data to multiple siloed environments and minimizes data risk for Enterprises.
- Increased efficiency: Data analysts and data scientists are able to quickly build business processes within a data sandbox.
- Data-backed decisioning: A sandbox can enable data backed decision making by quickly analyzing the available data or building new transformed data sets.
However, enterprises may encounter challenges governing and managing not only the data within the sandbox, but also the processes being created in that space. And the bigger your sandbox, the more challenging it is to manage.
Data sandbox challenges
Many times, the processes built in a data sandbox become business critical and the sandboxes can be pseudo in-production. Organizations then face the challenge of managing and governing the data and processes in the sandbox.
Some key challenges include:
- No defined path to production: Since these processes are built in a sandbox by a data analyst, many times a tech team needs to be involved in order to productionize these processes.
- Lack of automated monitoring and alerting: Data sandbox processes do not have standardized monitoring and alerting capabilities, which can impact critical processes that are dependent on the data in the sandbox environment.
- Manual processes for data governance: The data analyst and scientist community may not be well-versed in an organization’s data governance processes, so those processes often get missed during the build phase.
- Data silos are being created: If there are no governance controls, in most cases it can lead to duplication of the same data.
A sloped-governance approach
All data is not created equal, so having the same data governance standards and controls across different types of datasets can slow down analysts. Using a sloped governance approach, you can increase governance and controls around access and security for each ascending level of data.
For example, private user spaces can have minimal data governance requirements since they don’t have any shared data. As you move the pyramid (see fig. 1), the controls get stricter and take more time to be implemented.

As Capital One began exploring a platform to enable sloped governance in our own organization, we wanted to keep the following features in mind:
- The tool needed to be self-service to ensure usability.
- Metadata needed to be automatically captured to reduce manual data entry.
- Automated monitoring was necessary to help platform owners see what is going within the platform, and to help users better support and monitor their processes. Alerts also needed to be set up for approvals, progress, and process failures.
- It was essential that there be the ability to move sandbox processes into a production environment for better management.
- We also needed to make sure we have the right data access and security pattern established for the data in the sandbox.
How Capital One built a platform for managing and governing the data sandbox
Data is part of Capital One’s DNA, and we have been leveraging data sandboxes even before we transitioned to the cloud and to Snowflake. When we started the migration to cloud we had this massive sandbox environment, which was being leveraged in our legacy data platforms.
This led to a few challenges when we started our cloud migration, including a lack of ownership of processes running in the sandbox, no standardization of how data pipelines were executed or monitored, and critical downstream processes were not captured.
Based on these challenges, we realized the need to build a well-governed sandbox and enable our data analyst and scientist community with the right set of tools to be even more productive and agile. We had four key pillars:
- Sandbox creation: We knew that they would need the ability to create a sandbox in a self-service manner.
- Process and access management: We wanted to simplify access management, and make it as automated as possible.
- Governance: Governance is key for any big organization like Capital One, but it was important not to burden the analysts with this responsibility.
- Pipeline to production: The idea behind building an automated pipeline was to enable a data analyst or scientist to move their processes to production without involving any technology teams or duplication of work.
Sandbox creation
In the past, creating a new sandbox was a manual process involved. Additionally, the analysts were dependent on central DBA teams to provision the sandboxes, which could become a bottleneck and slow the teams down. In our new platform, we wanted to have a self-service capability for our analysts, but not compromise on any of the process requirements.
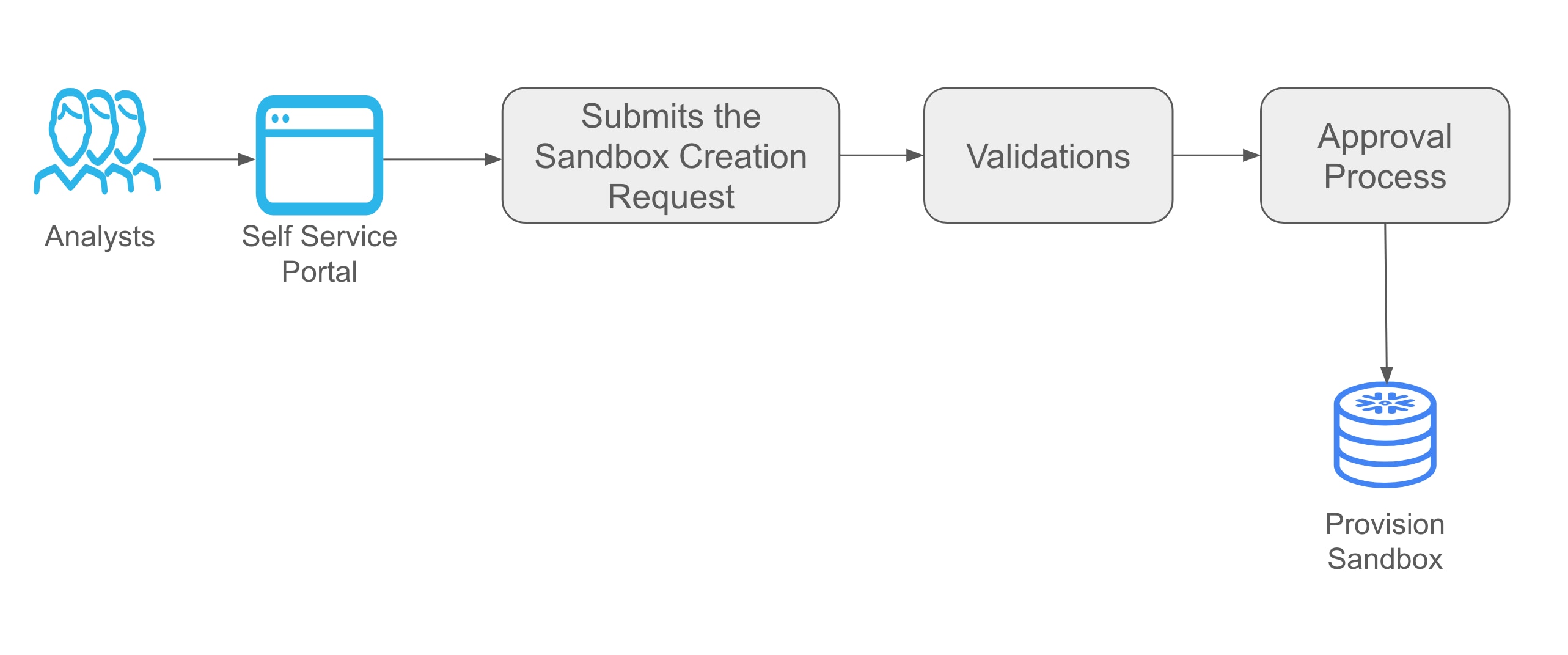
To do this, we isolated the data sandboxes by creating different schema's within our Snowflake environment. We also built certain automated validations within the platform so that we could have standardization across different sandboxes in different lines of business.
There is always room for error when a process is manual, so we built approval workflows within the tool to ensure there is ownership and accountability on what was built in the sandbox environment. This helped us streamline the entire process and still enable the analyst community to move quickly.
Access and process management
When we talk about process management, we are referring to a data processing job being built by an analyst. We wanted to provide a standard platform for our analysts to create these jobs, schedule them to execute on certain intervals, and also provide proactive and automated monitoring. We also wanted to address access management for these newly built sandbox objects, as well as the data being used in the processes.
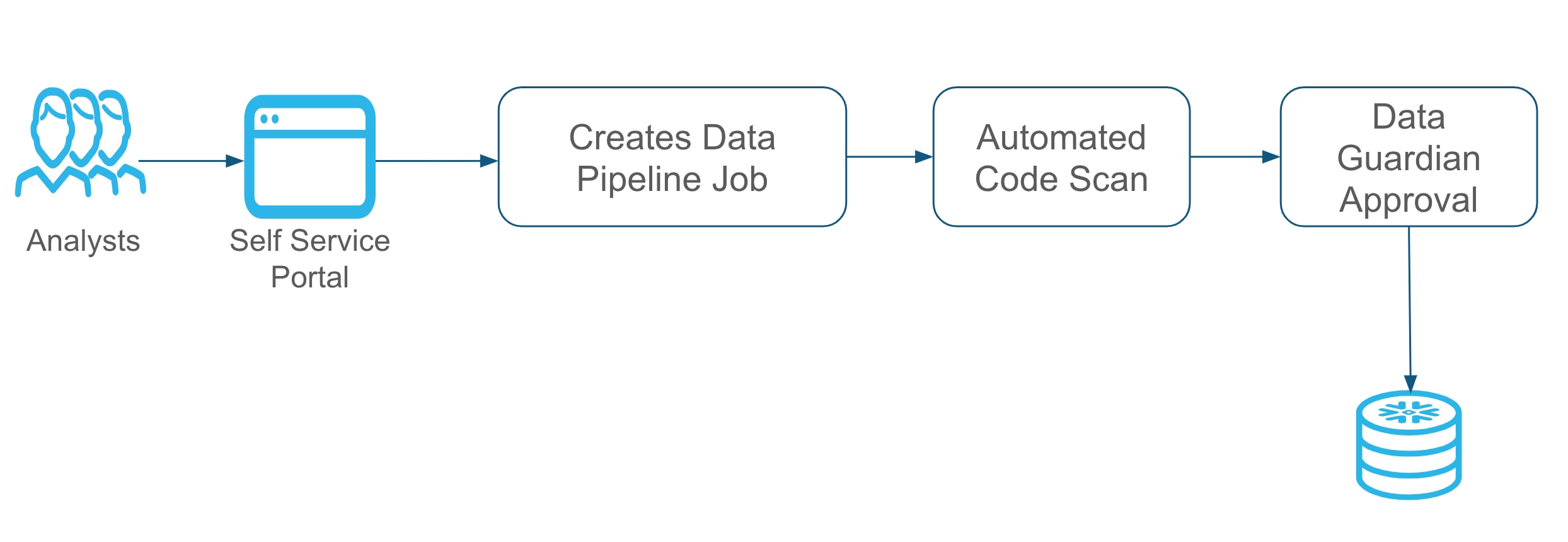
We leveraged Snowflake Tasks to schedule the data analyst jobs in our Snowflake environment. The capability to run jobs at certain intervals really provided the flexibility to the analyst. Using tasks dependencies also allowed us to set up job dependencies and build entire workflows.
Additionally, we built SQL scanning capabilities that could analyze an analyst’s SQL code and request the right access needed to perform the job. We leveraged Snowflake's role based access control to grant access to the right objects for the right user. A self-service UI also helped abstract all the complexity from our analyst community.
Governance automation
A good data governance practice can lead to stronger policy adherence, more accurate analytics, improved data quality, lower data management costs, and increased access to needed data for users.
If an analyst needs to satisfy all governance policies manually, it takes time away from business critical work. We saw the need to automate a lot of the governance policies within our platform, for example:
- What's in my Sandbox?
- How long is the data needed?
- Who is using my insights?
- Is the data good?
- How secure is my data?
We automated the capturing of data lineage by leveraging the access logs tables provided by Snowflake. Metadata for the tables were extracted from the Snowflake DDL.
Data retention was also automated. Our enterprise retention policies were implemented within the tools so that analysts don’t have to worry about data purging or archival. These policies are customizable to accommodate the changes to policies.
Finally, we automated the process of checking the data quality and also gave a way for our analyst to define the data quality rules in an easy way. Using the snowflake rich SQL functions we were able to execute the complex data quality rules within the Snowflake platform.
Automating these governance policies has not only saved our analysts’ time, but also ensured we meet our enterprise governance needs.
Pipeline to production
The analyst community has been building business critical processes in the sandbox environment for a while now, but these processes cannot live in a sandbox forever. We needed to find a way to move these processes into production so any valuable insights generated could be used across the organization.
This brings us to the last piece of the puzzle. Usually moving a process to a production environment is cumbersome and manual. We focused on building a self service process to move these data processing jobs and the associated data to a production environment.
We enabled different lines of business to build their custom approval workflows to be used during the migration process. For example, based on the criticality a process could need one approval or multiple approvals. Everything in the platform was audited to meet any compliance requirements.
Each step of our migration flow was automated, including request creation, access request, metadata capture, approval, promote to production, and monitoring.

Realizing the value
Since building the platform, we have seen a ton of value. We have thousands of users across multiple lines of business leveraging the tools, and have saved thousands of hours that were previously spent on manual change management processes. We’ve also enabled real-time alerting for the thousands of data sandbox processes, and have provisioned many sandboxes in minutes with the right governance and controls.


