Data lake architecture: Zones explained
Why we need zones in a data lake, and best practices to use them
It is a commonly asked question in the world of Data analytic systems – Why do we need zones at all in a data lake? So what if the data is all lumped in a data lake? Surely, access can still be controlled individually. One aspect that immediately comes to mind as it relates to a data lake is the capability to store high volume and veracity of data in an unlimited storage medium.
However, oftentimes, too little emphasis or importance is placed on making this data consumable. To provide clarity to this question, we need to think of a data lake beyond storage. After all, what good is the data in it if it is beyond the reach of consumption. It's akin to "Water water everywhere, not a drop to drink. ''. This blog is my attempt to unravel the shift (technical and mindset) required to think of a data lake in terms of consumption.
While data is considered the king for analytics, not all data is made equal and with the explosion of consumption use cases, mediums, and tools, data in various forms and states serve a specific purpose and can be consumed differently.
Enterprise analytic store data lake at Capital One, in its current state, has been a "No zone" lake. There is active ongoing Tech enhancement in progress in this space. As we think about the big picture, fundamental questions need to be answered from a value proposition standpoint. Why do we need this shift?
Common data lake use cases
In line with how we perceive the data in the lake and its usage thereafter, one can expect the usual suspects as responses. The usual suspects go like this:
- A data lake by definition is a home to potentially different kinds of data (structured, semi-structured, unstructured to name a few). If all of this is dumped into a data lake with no distinguishing characteristics, it becomes a swamp. In other words, a data store whose primary purpose is to aid in analytics becomes a mere "dump and forget" store and no meaningful business value can be extracted.
- Another rationale is to avoid a one-size-fits-all scenario from a storage perspective.
- There is also the notion of the quality of data in the lake that is routinely cited as the reason for having zones. What data truly represents the ground truth in a lake and the management of it.
These are all valid reasons, yet most are tilted in favor of the storage aspect of a data lake.
Practical applications of data lake
Think about consumption and the different consumer groups. A data lake is only as good as the sum of its parts. In other words, if the data in the lake cannot be clearly isolated and cater to different flavors of analytic consumers, then it stops adding value for analytics.
For a data lake to be effective as a business value added tool, there needs to be an element of progressive data cleansing of data as it gets injected all the way until it is ready for consumption.
This requires an approach that moves away from looking at a data lake purely from storage perspective as a monolithic store and more as a consumption store that clearly distinguishes data in terms of its type, access, degree of data quality, lifecycle and consumption behaviors.
Zoned separation of data lake for faster recovery
Zoned separation of data in a lake enables faster discovery of data. Data lake zones act as stage gates. Every gate has a specific function with no overlaps among them on what the data there represents and its consumption pattern. In other words, data in a lake should go through a journey to ultimately render it consumable.
The reason we at times struggle to justify structuring the data lake as zones lies at the heart of the set up - Predominantly from the perspective of Storage and not consumption. A lake design that represents a monolith of AWS S3 data objects with one zone is not consumption friendly. I consider this to be a basic data storage approach where much of the governance is offloaded upfront and all types of data are attempted to be standardized before injection.
In other words, we have made consumption from the data lake rigid where data is limited to one set of consumers, but also without the ability to guarantee the integrity of the data being consumed. The net effect of this design is that it has ensured data to be brought in, but made consumption many folds difficult and unwieldy.
Consumption in turn requires data trust. Much of what ails a no-zone lake is the lack of trust in the data and there is considerable technical debt involved in ascertaining the consumption quality and the degree of the data. A well designed multi zoned architecture removes this ambiguity greatly as the data is processed through a series of stage gate processes.

High level schematic of single / no zone lake
Single zone lake
Although for the sake of brevity, I have simplified the above diagram, the spirit of the layout is clear. The data lake does not contain a delineation of data within it and stays true to the storage aspect. In other words, it is incorrectly presumed that as long as data is somehow available in the lake in any manner, it can be consumed readily by all.
Multi-zone lake
Every zone has unique properties and defines a set of attributes. It could be the degree of the processing state of the data itself or where it is sourced from or its lifecycle or how it may be consumed.
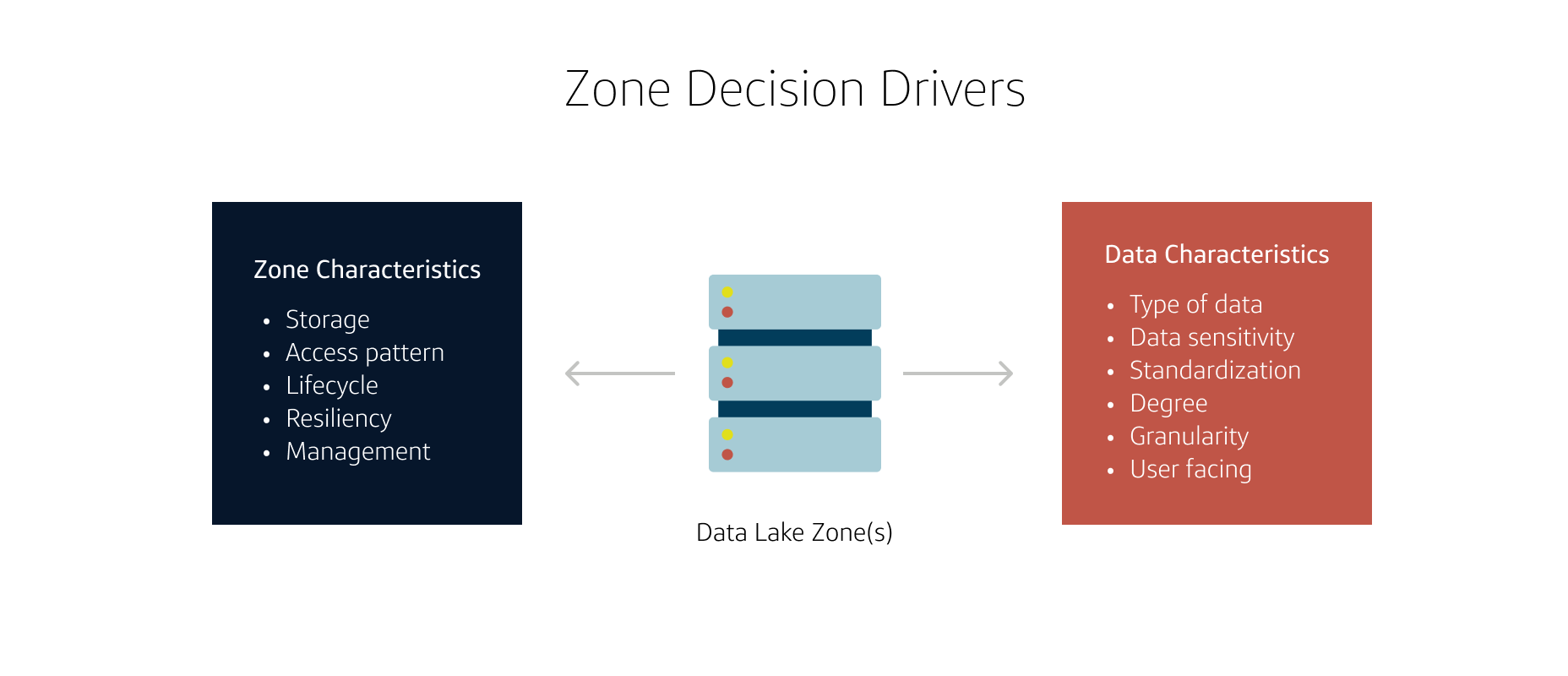
As depicted above, a zone definition encompasses the set of criteria that is unique to the zone in terms of its persona as well as the data it manages.
Data lake zones and characteristics explained
Below is a sampling of how this representation can fit into the zone definitions laid out above:
-
Landing/raw zone
A landing/raw zone acts as a governed first level entry point for the lake to house a variety of data with high velocity satisfying both batch and stream use cases. Its purpose is to preserve the source data in its native format and has a preset lifespan and is not generally user facing.
-
Standardized zone
A format standardized zone can be a governed user facing (or can sometimes act as intermediary staging standard) zone optimized for use case driven analytics with appropriate data retention policies and format standardized for the purpose of schema consolidation and performance. It is generally accompanied by standardization related transformations and/or tokenization for obfuscation of sensitive data. It is usually associated with a higher degree of data quality than the raw zone.
-
Consumption zone
A consumption zone is the ultimate user facing zone and houses use case driven end data products with required transformations. Its lifecycle and access patterns are largely governed by the analytic operations and consumers and is tightly regulated and highly resilient.
-
Exploratory zone
An exploratory zone enables ML use cases and acts as a play area for model exploration. Its governance, data completeness and lifecycle requirements differ from other zones. The final result may yet be made consumable and can be format standardized into its specific zone.
The above list can be extended with abundant scope for flexibility and interchangeability. It is important to note that the individual properties dictate the characteristics of the zones and they are personalized and controlled at that level and not as a monolith. This enables targeted access to different varieties of consumer groups and the guessing game of what that data represents is avoided thus saving valuable time for consumers.
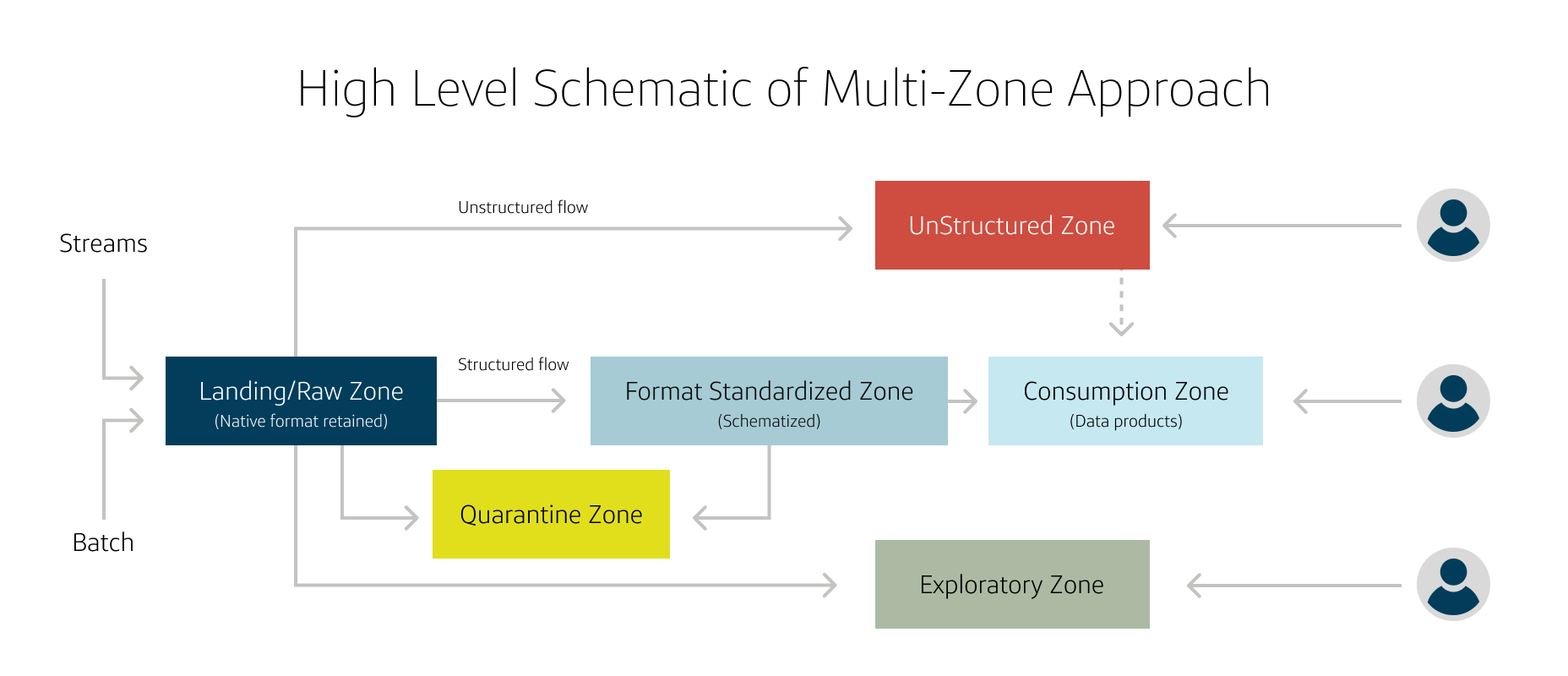
It is clear from the above diagram that defining the zones and segmenting the data in the lake accordingly re-orients the data lake from the perspective of consumption. Storage becomes just one of the properties of a zone that needs to be managed.
No-zone (single zone) models
A single zone model (or more appropriately a no-zone model) cannot handle the uniqueness associated with each of the zones. It becomes an either/or proposition on setting independent boundaries. The interoperability of the zones within the lake enables the data to mature as it comes in. Needless to say, every organizational use case and impetus to create a data lake is different. In this regard, zones provide the flexibility to tailor them from the perspective of consumption.
It is a misnomer to think of "fit-for-purpose" to only apply as a warehouse terminology. Consumption of data in the data lake from certain user facing zones helps us realize the same while retaining the distinct differences between them. A consumption zone that houses fully formed data products falls in this category.
Practically, not every piece of data is user facing or consumable. Some are there to fulfill their part in the lifecycle journey of the final consumable data. Hence, there is a clear separation of concern between storage and consumption.
Key takeaways for data lake architecture with multi-zones
-
Streamline consumption
Traditional yesteryear rationales aside, it is important to reorient the mindset of using a data lake towards being strongly consumption centric. Storage takes care of itself in a data lake as that is its native state while making it consumption friendly requires work. A no-zone lake is more aligned to a storage paradigm. A multi-zone model lake offers data delineation and allows the unique characteristics of individual zones to shine through and serve their charter of streamlining consumption.
-
Enhance data trust
Data in the zones offer enough uniqueness that renders them to correlate with appropriate consumer groups. A well architected zone strategy enhances data trust and removes the ambiguity on the degree and grain of the data - An exercise the consumers feel burdened with quite often.
-
Start small with individual zones
Start small and have just the required zones. Avoid over-engineering pitfalls impeding interoperability. Let the individual zone criteria be your guide.
-
Avoid duplicating data
Avoid data duplication across zones. While it may be tempting, as a quick fix, to just import/copy data to another zone to make a specific use case work, this will prove counter-productive in the long run. Apply appropriate controls and lifecycle/data retention policies with no exception.
-
Control access
Control access by differentiating what is user-facing vs. what is internal, technical and transient and apply those rules for access.
I am hopeful that this discussion on practical use of zones will convince the reader to focus their attention more on the consumption of a data lake. A well planned multi-zone architecture for a lake enables achieving this goal.


