Fintech—How serverless transactions better serve customers
We’re in the midst of a sea change in banking technology. Many large financial institutions rely on monolithic, legacy mainframe systems as their core banking platforms. This approach worked for decades; however, with the recent adoption of Cloud services and DevOps practices (modern stack), this legacy approach is no longer the best way to serve our customers.
There are big challenges with building digital products on top of mainframe systems:
- Changes to monolithic systems require a long release cycle to production
- Cost per GB is much larger than a comparable storage system in the Cloud
- Compute cycles (MIPS) are expensive
- Scaling requires costly upgrades
- Capacity is usually based on peak traffic
Innovation and experimentation are cumbersome due to complex dependencies
Serverless systems offer obvious advantages: faster SLA’s for presenting data back to various channels, improved integration with big data analytics, and better uptime, scalability and maintenance. More importantly, with serverless we can incorporate best DevOps practices―enabling the continuous delivery of digital products into the hands of consumers.
The challenge then becomes how to extract and make available data and processes related to Consumer accounts and financial transactions on modern cloud-based serverless infrastructure, within a system that is scalable, reliable, and extensible.
First, decide what to migrate
A mainframe is a complex system where any change requires analysis of a deep web of dependencies. We determined that in our legacy systems, close to 80% of the traffic was related to reading transactions. This insight gave us our focus: implement a system in the Cloud that would serve the read-only traffic and be fed by the mainframe in batch and in near real-time modes.
Second, establish success criteria
- Here’s what our team agreed that serverless needed to deliver:
- Built in the Cloud and served via scalable APIs
- Handles large scale traffic as well as any type of spikes in traffic (e.g., Black Friday, etc).
- Follows DevOps best practices
- Seamlessly scales when demand increases
- Supports batch and real-time workloads
- Provides consistent performance at any load (equal to or better than legacy systems)
- Cost effective (cheaper than mainframe per transaction)
- Does not compromise on security (Data at rest and in motion encryption)
- Easily integrates with other services (real-time fraud analytics, etc)
Given our stated success criteria, we leaned heavily in favor of a serverless architecture because it enhances the ability to ship product/features faster into the hands of customers while improving scalability and lowering costs both in terms of computing power and human resources.
Empower talent to solve problems
We assembled a cross-functional team of top-notch engineering talent, and challenged them to solve the problem of improving the response times for read-only requests for transactional data, with a lean towards serverless architecture.
With the high-level challenge set, we identified the following additional problems that had to be solved:
- Choosing a datastore in the cloud (we opted for DynamoDB)
- Loading billions of transactional records into DynamoDB
- Creating a messaging infrastructure to keep transactions available on the mainframe and in our cloud-based system in sync near real-time
- Building a new version of the getTransactions API in the cloud
- Migrating traffic from all channels from the Mainframe system to our cloud-based system
This is the business case for going serverless. Once we agreed on what success looks like, there were many technical and architecture challenges that our engineering teams faced. Here are highlights of what we learned along the way.
High level approach—CQRS pattern
A Command Query Responsibility Segregation pattern is an approach where applications maintain two different data models—one to do “updates” and one for “reads”. This pattern proved invaluable for our challenge to maintain transactional data sync between a large, monolithic mainframe system and a cloud-based datastore. However, using separate data models raises an obvious challenge of keeping those models consistent. which raises the likelihood of using eventual consistency. Below diagram depicts a logical view of how the read traffic across all channels migrates to the new destination serverless architecture.

Security
The security of our customers’ financial transactions is of paramount importance. All data is encrypted at rest and in transit, and we leverage our point to point authentication mechanisms to ensure only authorized callers have access.
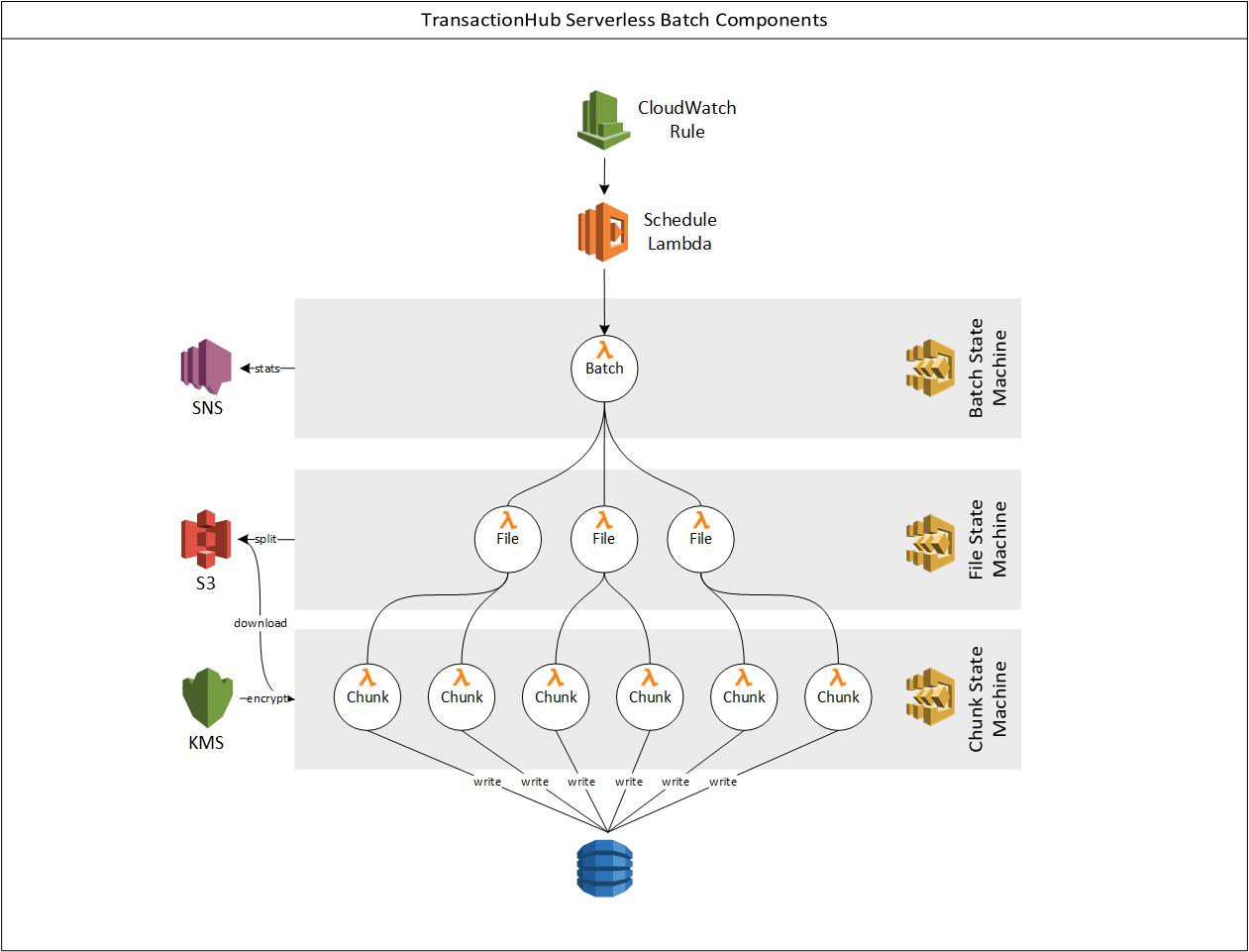
Logical architecture diagram
As you can see in the picture above, there are various serverless components in the architecture.
- Lambda functions to trigger arrival of transaction files from the mainframe
- Lambda functions to maintain the state of the files
- Lambda Functions to read and ingest data into DynamoDB
- Lambda functions to provision WCU and RCU dynamically on DynamoDB
- DynamoDB as the read-only datastore
Business monitoring
We treated monitoring as a first-class citizen and wanted to make sure we built a system which not only can be monitored easily, but also can provide real-time alerts when things go wrong.
We chose Elastic Stack, Cloudwatch and SNS as part of our monitoring system. Cloudwatch was used for all the logging, SNS for alerts, and Elastic was used for dashboards. We built Kibana dashboards which are updated in real-time and are constantly monitored for any anomalies.
Best practices
Know your data: Data files provided by the source system (mainframe) were sorted by primary key. This caused massive throttling during ingestion due to hot partitions in DynamoDB. The problem was solved by shuffling the data in the files before ingestion, so writes were distributed to multiple partitions in parallel.
Always test at scale: During our initial load/ingestion tests, we did not experience throttling. Once we started to ingest at scale, we began to observe throttling due to hot partitions. This gave us an opportunity to review our table design and make corrections to keys used in the DynamoDB tables.
Know your access patterns upfront: It is important to have well-defined access patterns before tables/indexes are designed. If not designed correctly upfront, there will be performance issues after data is ingested and this will require re-ingestion and re-creation of the tables/indexes as the keys in the tables/indexes cannot be changed once created.


