Tips to fine-tune sentence-BERT for question matching
A simple BERT language model tutorial on using the sentence-transformers library.
Updated December 20, 2023
I’m Alison, an engineer at Capital One focused on developing an internal question answering chatbot. At Capital One, slack serves as a primary medium for team communication, hosting numerous channels ranging from software deployment to corporate travel. Within each channel, recurring questions frequently arise. To automate responses to frequently asked queries, we established a Slack bot, which has found its place in over 130 internal Capital One Slack channels, some having over 1,000 members.
When a team wishes to add our bot to their channel, they create a set of question-answer groups consisting of (1) multiple ways of phrasing a certain question, and (2) the question variants’ corresponding answer. In production, the bot uses these question-answer groups to fine-tune a BERT language model - more precisely, the Sentence-BERT model to match incoming Slack messages against known questions. When the bot receives a message in a Slack channel, it can reply with question recommendations or questions closely matching the incoming message. When a question recommendation is clicked on, the bot replies with the answer corresponding to it.
Over time, the set of question-answer groups can be revised and the model fine-tuned again. The model we use for question matching is BERT (Bidirectional Encoder Representations from Transformers), specifically Sentence-BERT. This article offers insights into fine-tuning the BERT model, especially the Sentence-BERT for question matching, drawing from my experience crafting the bot for Capital One.
What is sentence-BERT?
Sentence-BERT is an extension of the BERT model dedicated to word embeddings. Word embedding models are used to numerically represent language by transforming phrases, words, or word pieces (parts of words) into vectors. These models can be pre-trained on a large background corpus (dataset) and then later updated with a smaller corpus that is catered towards a specific domain or task. This process is known as fine-tuning.
Highly efficient word embedding models encapsulate textual meaning, including its context. For example, the vector representation of the two different words sleepy and tired will be very similar because they tend to appear in similar contexts. BERT, from which Sentence-BERT is derived, is one of these high-performing models. It was developed by Google researchers in 2018 and trained on over 11,000 books and the entirety of Wikipedia.
We chose Sentence-BERT specifically because it has been optimized for faster similarity computation on the individual sentence level, which makes it a great fit for our question matching task. As you can see in the tables below, Sentence-BERT performed very well on a variety of NLP tasks, most notably for our use case on Semantic Textual Similarity (STS).
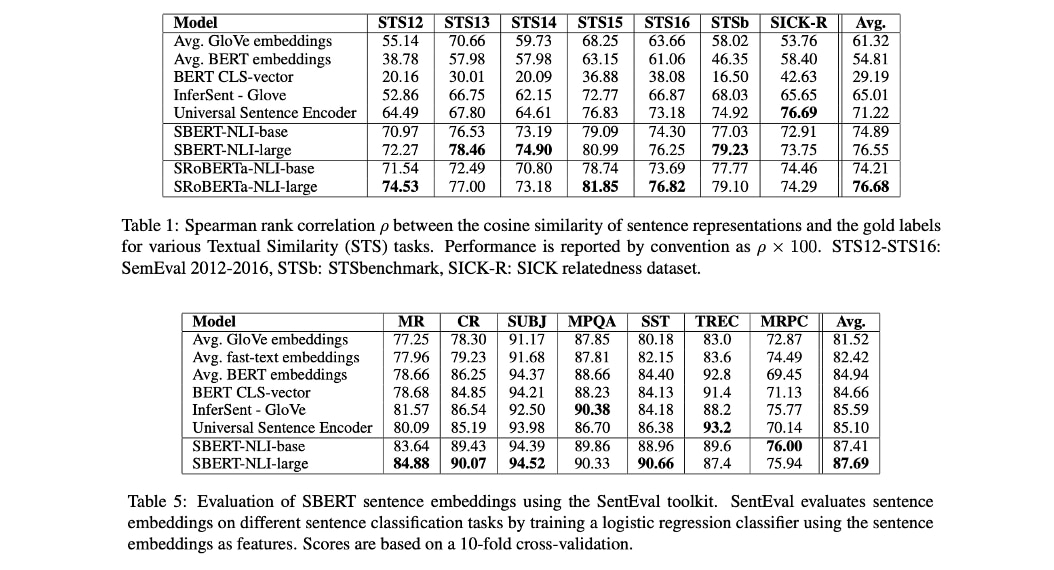
Although it is possible to get meaningful results with just the pre-trained Sentence-BERT model, we saw a huge difference in accuracy between the pre-trained model and the model that we fine-tuned using just 7,000 new utterances (questions and answers) from our own Slack data. When evaluating the two models on 200 new test questions, question matching accuracy was 52% for the pre-trained model and 79% for the fine-tuned model. Accuracy increased further as we increased the amount of data used for fine-tuning.
Tutorial: How to leverage sentence-BERT for question matching
Say we want to use Sentence-BERT to determine which question-answer groups most closely match an incoming Slack message.

We use the sentence-transformers library, a Python toolkit tailored for cutting-edge sentence and text embeddings. We systematize our data, fine-tune BERT for question answering, and subsequently deploy the refined model for question matching.
Sentence-BERT data example
Let’s say we want our bot to answer questions about a cooking blog. Our dataset has three question groups. Each group contains a few question variations and a corresponding answer. The more question variations, the better, but to keep this Sentence-BERT tutorial simple, we’ll use just a few.
| # | Questions | Answers |
|---|---|---|
| 1. |
What should I cook after work? What are some one-pot meals I can cook? What are some easy recipes to make? |
For easy one-pot or weeknight recipes, please access this [link]. |
| 2. |
Do you have advice on how to get started with cooking? How do I substitute things in recipes if I don't have all the right ingredients? |
Beginner cooking tutorials can be accessed [here]. |
| 3. |
Where can I review your recipes? I found a typo in one of your recipes. I would love it if you added more dairy free recipes to the blog. |
Did you try one of our recipes or cooking tutorials? [Here] are the ways to leave feedback and suggestions. |
There is a many-to-one relationship between questions and their corresponding answers. We have three question-answer groups, each with two or three question variations. We want the model to learn the semantic relationships between the questions within each group. For example, if we take two example questions from group 1 and use the model to convert each one into a word embedding vector:
What are some one-pot meals I can cook? → v1
What are some easy recipes to make? → v2
We want v1 and v2 to be close to each other according to a distance metric like cosine distance. On the other hand, if we take a message from group 3, I found a typo in one of your recipes, and convert that to v3, we want v3 to be distant from both v1 and v2 according to the same metric.
Triplet loss
During each iteration of the fine-tuning process, we select an anchor vector v1 to focus on. We then select a positive and a negative data point for comparison: V2 from the same group as v1 and v3 from a different group. We then minimize the distance between v1 and v2 (anchor and positive) while maximizing the distance between v1 and v3 (anchor and negative). The loss function for this optimization is known as triplet loss.

III. Inputting Data to the Model
Let’s look at the final data we input into the model for fine-tuning. We put this data into a TSV file where each row contains a group number followed by the question or answer text.
| 1. | What should I cook after work? |
| 1. |
What are some one-pot meals I can cook? |
| 1. |
What are some easy recipes to make? |
| 1. |
For easy one-pot or weeknight recipes, please access this [link]. |
| 2. | Do you have advice on how to get started with cooking? |
| 2. | How do I substitute things in recipes if I don't have all the right ingredients? |
| 2. | Beginner cooking tutorials can be accessed [here]. |
| 3. | Where can I review your recipes? |
| 3. | I found a typo in one of your recipes. |
| 3. | Did you try one of our recipes or cooking tutorials? [Here] are the ways to leave feedback and suggestions. |
Notice that we’ve included the answers at the end of each numbered group. While answers are typically structured differently than their associated questions, they often include a rephrasing of parts of their questions or other relevant information. We found that the model can learn from this semantic relationship. Including the answers in the data for fine-tuning, even when only the questions were used for comparison during the inference process, made a significant difference in question matching accuracy.
IV. Fine-tuning the BERT Model
Now that our data is ready, it's time to fine-tune the BERT language model. The below code is a toy example—I’ve had success using over 7,000 data points but have not tried using fewer, and you’ll need to tweak the batch size and number of epochs depending on how much data you have and what you find performs best. You may also want to use TripletEvaluator on test data during the fine-tuning process, but to keep this tutorial simple, I haven’t included it here.
# sentence-transformers==1.0.4, torch==1.7.0.
import random
from collections import defaultdict
from sentence_transformers import SentenceTransformer, SentencesDataset
from sentence_transformers.losses import TripletLoss
from sentence_transformers.readers import LabelSentenceReader, InputExample
from torch.utils.data import DataLoader
# Load pre-trained model - we are using the original Sentence-BERT for this example.
sbert_model = SentenceTransformer('bert-base-nli-stsb-mean-tokens')
# Set up data for fine-tuning
sentence_reader = LabelSentenceReader(folder='~/tsv_files')
data_list = sentence_reader.get_examples(filename='recipe_bot_data.tsv')
triplets = triplets_from_labeled_dataset(input_examples=data_list)
finetune_data = SentencesDataset(examples=triplets, model=sbert_model)
finetune_dataloader = DataLoader(finetune_data, shuffle=True, batch_size=16)
# Initialize triplet loss
loss = TripletLoss(model=sbert_model)
# Fine-tune the model
sbert_model.fit(train_objectives=[(finetune_dataloader, loss)], epochs=4,output_path='bert-base-nli-stsb-mean-tokens-recipes')
V. Inference
Now that we have the new fine-tuned model, we can transform any text. For our task of recommending questions to be clicked on in order to receive their associated answers, we use cosine distance to determine the semantic similarity between a Slack message and known questions.
For simplicity, we compare new questions to known questions and not to answers. However, we could also compare the new questions to answer options directly, especially since we’ve included the answers in the fine-tuning process.
In production, it’s useful to precompute question vectors and store them along with their corresponding answers. This allows us to quickly calculate the distance between an incoming message and existing questions, sort by distance, and then provide the answers corresponding to the questions closest to the incoming message. However, for the sake of simplicity, reading the pre-stored data from a database or file is not included in the sample code below.
Let’s say we have just received the Slack message Hello chefs, I would like to get started with some easy recipes. Any suggestions? Here are the steps we take to produce relevant questions and answers. 1. Convert an incoming Slack message to a vector using our fine-tuned model.
SAMPLE INPUT:
new_question = """Hello chefs, I would like to get started with some easy recipes. Any suggestions?"""
recipe_model = SentenceTransformer('bert-base-nli-stsb-mean-tokens-recipes')
encoded_question = recipe_model.encode([new_question])
2. Compare the resulting vector to all the precomputed question vectors in q_a_mappings, sort, and display the top n matches. In this example, we display two matches. We store question vectors (embeddings), question texts, and answers in three parallel lists of the same length. This way, associated embeddings, questions, and answers are all conveniently located at the same index of each list. The similarity computation code is inspired by this example.
# scipy==1.5.4, numpy==1.19.5
from scipy import spatial
import numpy as np
q_a_mappings = {'Question Embedding': [[ ], [ ], [ ], …], 'Question Text': ['What should I cook after work?', 'What are some one-pot meals I can cook?', ...], 'Corresponding Answer': ['For easy one-pot or weeknight recipes, please access this [link].', 'For easy one-pot or weeknight recipes, please access this [link].', ...]}
question_embeddings = q_a_mappings['Question Embedding']
question_texts = q_a_mappings['Question Text']
answer_mappings = q_a_mappings['Corresponding Answer']
distances = spatial.distance.cdist(np.array(encoded_question), question_embeddings, 'cosine')[0]
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
for idx, distance in results[0:2]: # just getting top 2
print(f"\nMatch {idx+1}:")
print(question_texts[idx])
print(answer_mappings[idx])
SAMPLE OUTPUT:
Match 1:
What are some easy recipes to make?
For easy one-pot or weeknight recipes, please access this [link].
Match 2:
Do you have advice on how to get started with cooking?
Beginner cooking tutorials can be accessed [here].
Fine-tuning sentence-BERT for question matching: Key takeaways
That concludes our walkthrough on harnessing the sentence-transformers library to fine-tune BERT for question answering. Fine-tuning Sentence-BERT with your own data can significantly improve the accuracy of question matching for your specific task.
In this article, I shared some tips on how to fine-tune Sentence-BERT for question matching, based on my experiences building an internal chatbot for Capital One.
Here are some key takeaways:
-
Use triplet loss to fine-tune the model.
-
Include the answers in the fine-tuning data.
-
Precompute question vectors and store them along with their corresponding answers for faster inference.
Please check out the library documentation for many more ways of using it.


