Effect of positional encoding on graph transformer models
Capital One’s research on how graph models are used in finance and how positional encodings affect different graph transformers.
This blog was authored by the 2024 UMD Tech Incubator intern cohort
Capital One created two campus Tech Incubators at University of Maryland (UMD) and University of Illinois (UIUC). These physical spaces are home to the Tech Incubator internship. Interns are hired from these universities year-around to work on emerging AI and ML capabilities within the company.
The UMD summer 2024 intern cohort authored this blog, featuring Capital One’s research on how graph models are used in finance and how positional encodings affect different graph transformers. Let’s dive in.
Graph-specific machine learning techniques
Graphs are a useful way to model relationships in data. For a basic definition, graphs consist of nodes and edges which represent entities and connections between them that are difficult or impossible to represent in other data structures. In financial services, graphs can be used to model complex relationships between merchants and vendors for a variety of tasks ranging from recommendation algorithms for advertising to fraud detection and risk analysis.
However, standard machine learning techniques are not well-suited for extracting signals from graphs. So, we use graph-specific machine learning techniques, such as graph convolutional networks and graph transformers, to tackle problems like node classification and link-prediction. Graph transformers in particular have shown promising results in many downstream tasks. However, there are avenues for improvements to be examined, for example, regarding hyperparameter tuning and positional encodings. This article will mainly focus on the latter and discuss findings for how positional encodings affect two different graph transformer models.
What are graph transformers and what makes them unique compared to other graph neural networks (GNNs)?
Graph transformers are a type of neural network architecture designed to process data in the form of graphs. Taking inspiration from transformers used in natural language processing, they make use of a self-attention mechanism to factor in the importance of various nodes and edges, allowing for targeted processing of certain parts of an input graph. They also possess the unique ability to examine graphs in a global context, allowing them to understand a collective graph structure and distant relationships in the graph. Because of their ability to ingest nodes beyond the immediate neighborhood of an input node, graph transformers typically employ positional encodings. A positional encoding is a vector that is designed to represent the location of a given node in a graph. They are used to augment node embeddings to provide a notion of structure for the nodes in a graph.
In contrast to graph transformers, convolutional GNNs understand graph structures primarily through message-passing mechanisms. In this process, each node gathers information from local neighborhoods to derive its representation. GNNs typically iterate over multiple layers to propagate node and edge information. Because GNNs specialize in local-neighborhoods, they can often struggle with capturing distant relationships in graphs.
Experimental setup for training graph transformer models using different positional encoding techniques
Our experiments evaluate the efficacy of different positional encoding techniques. We trained 2 graph transformer models on 2 different open-source datasets using 6 different positional encoding techniques.
Models: GOAT and NAGphormer
We used two graph transformer models:
-
GOAT: A Global Transformer on Large-scale Graphs. In GOAT, an input node attends directly to its local neighborhood as well as attending approximately to the entire graph structure.
-
NAGphormer: A Tokenized Graph Transformer for Node Classification in Large Graphs. NAGphormer performs node classification by representing a node’s neighborhood as a sequence of tokens. The sequence is produced by sampling a neighborhood at varying distances from the input node via the Hop2Token algorithm.
Open Graph Benchmark (OGB) datasets
The Open Graph Benchmark is a collection of datasets that are used to perform various machine learning tasks on graphs. These datasets are highly diverse and realistic, making for a good benchmark when evaluating the performance of a model.
We used the following OGB datasets in evaluating our chosen transformer models for node property prediction accuracy:
-
OGBN-Arxiv: This is a relatively small (169,343 nodes), directed graph, which represents a citation network between technical papers on the arXiv paper distribution service. For our case, we used the arXiv data as a benchmark for our transformer models with node prediction. Using a predetermined split between training, validation, and testing, we examine how well GOAT and NAGPhormer perform on node classification in the arXiv graph, specifically, to predict which of 40 subjects a paper can be categorized into.
-
OGBN-Products: This is a medium sized graph representing a major retailer co-purchasing network where the prediction task is to find the category of a product. Products are much larger than the arXiv data with 2,449,029 nodes and are thus useful to examine the scalability of our transformer models for when we eventually apply them to real world graphs. Similar to arXiv, we also tested products with a classification problem of determining which of 47 categories a product falls into.
Positional encoding techniques
When choosing which positional encoding techniques to experiment with in training the GOAT and NAGPhormer models, there were multiple factors that needed to be considered for eligibility.
We asked the following questions when evaluating different positional encoding techniques:
-
Is the method of encoding inductive or transductive?
Inductive learning is an approach where models are able to learn to generate embeddings for unseen nodes that arise. On the other hand, in transductive learning, the entire graph is used in the training phase and in order to introduce new data, the entire model must be retrained. Graphs used in real world data are ever changing and it would be preferable for a model to be able to easily tackle new data to adapt to developments. -
Is it scalable? The encoding methods we chose needed to perform well for graphs with millions of nodes and tens of millions of edges.
Scalability is crucial when it comes to graph models being used in financial services. Real world data includes millions of nodes and potentially billions of edges and thus, any approach that cannot sufficiently scale to such large sizes would not be effective. -
What structure does the encoding technique capture? Local, global, or both?
Given the variety of encoding techniques, deciding between which methods to move forward with made the structural information captured an important consideration. Local structure in a graph refers to characteristics which are confined to a given node’s surrounding neighborhood. Positional encodings which capture global structures, on the other hand, hold information about the entire graph or its more large-scale patterns, focusing on the broader context of where the node exists. Hybrid approaches allow for a comprehensive understanding of graphs by balancing broader graph context with local neighborhood information.
After considering these criteria, we decided on the following techniques:
| Technique | Reasons |
| GraphSAGE | Provides an inductive method of generating localized low-dimension vector representation of nodes, allowing for scaling to unseen graph structures. |
| Node2Vec | Integrate distance-aware information in positional encodings, allowing for encoding node positions. |
| RWPE | Random walk positional encodings generate a vector of probabilities that a sequence of random hops will land on a given node starting from itself. |
| PageRank | Inspired by PageRank algorithm for ranking web pages. Used to rank graph nodes by importance by examining for each node both the amount of incoming edges as well as the importance of the nodes that those edges originate from. Provides information about the global graph structure but can be modified to examine local networks as well. |
| Laplacian Eigenvectors | An older but popular way of capturing positional encodings, laplacian eigenvectors combine information from the degree and adjacency matrix to capture global graph structure, node importance, and node similarities. |
| NoPe | Baseline to compare the use of positional encodings against node features without any positional information. |
Benchmarking/results for GOAT and NAGPhormer model training with the ArXiv and products dataset
A summary grid of the model training for GOAT with the ArXiv and products dataset is presented below. We plotted the training and validation loss of the model as well as gathered the accuracy for the test set in a table below.
GOAT model, ArXiv dataset
We note that in our 200 epoch model, most of the loss and accuracy curves have similar trends. It’s interesting to note the convergence rate for some of the models. Specifically, the validation loss for Laplacian positional encodings intersects with the training loss earlier than in many of the other models. We also notice that pagerank performed significantly worse than many of the other positional encodings methods and the loss curves seemed to be more unstable in the later epochs for both training and validation.

Results of the GOAT model training with the ArXiv dataset
GOAT model, products dataset
The results for the experiments on GOAT with products are much more erratic. As pictured below in the PageRank and GraphSAGE training runs, we observed spiking validation loss curves and even steadily climbing training loss across epochs. We suspect that the current hyperparameters are ill-fitted for the products dataset and suggest hyperparameter tuning to gain more definitive results. It’s also important to note that training the model for the products dataset was much more intensive than for ArXiv. It required GPUs (ArXiv was mostly done on CPU instances) and a large amount of memory, and, even then, training would take several days. As a result, our ability to iterate on these experiments was limited.
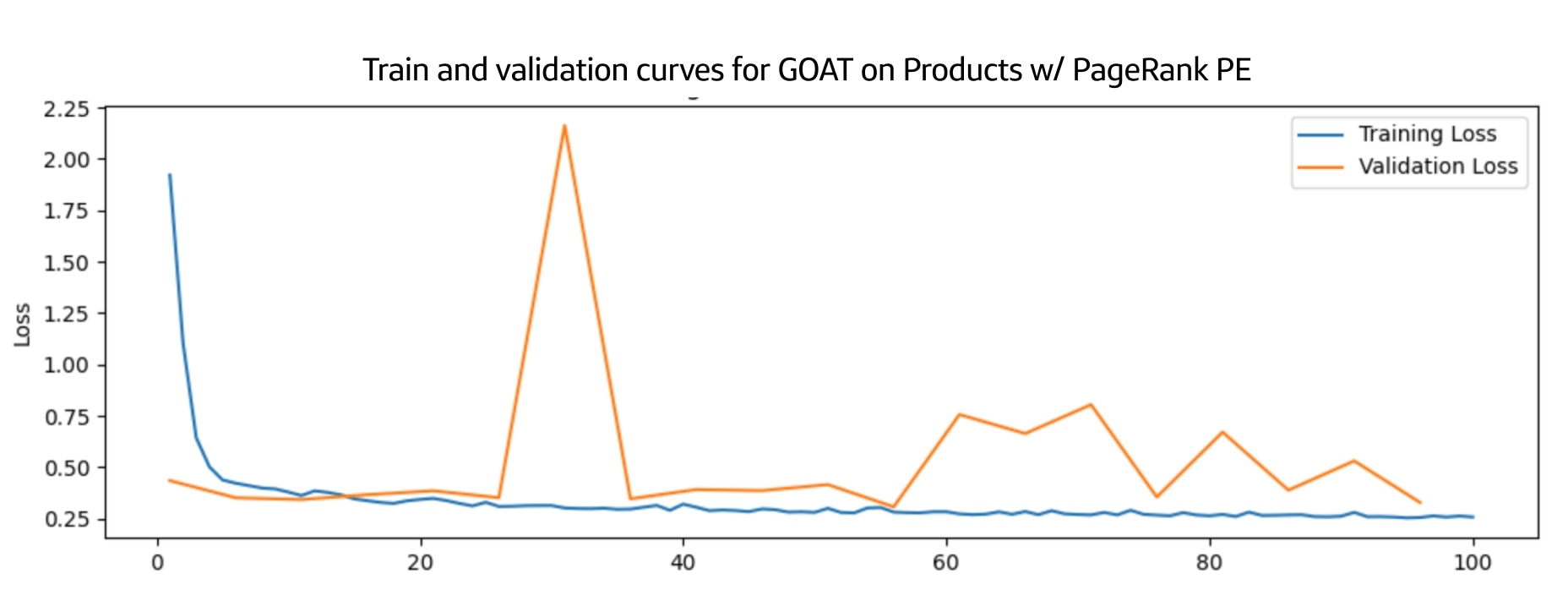
Results of the GOAT model training with the products dataset for PageRank
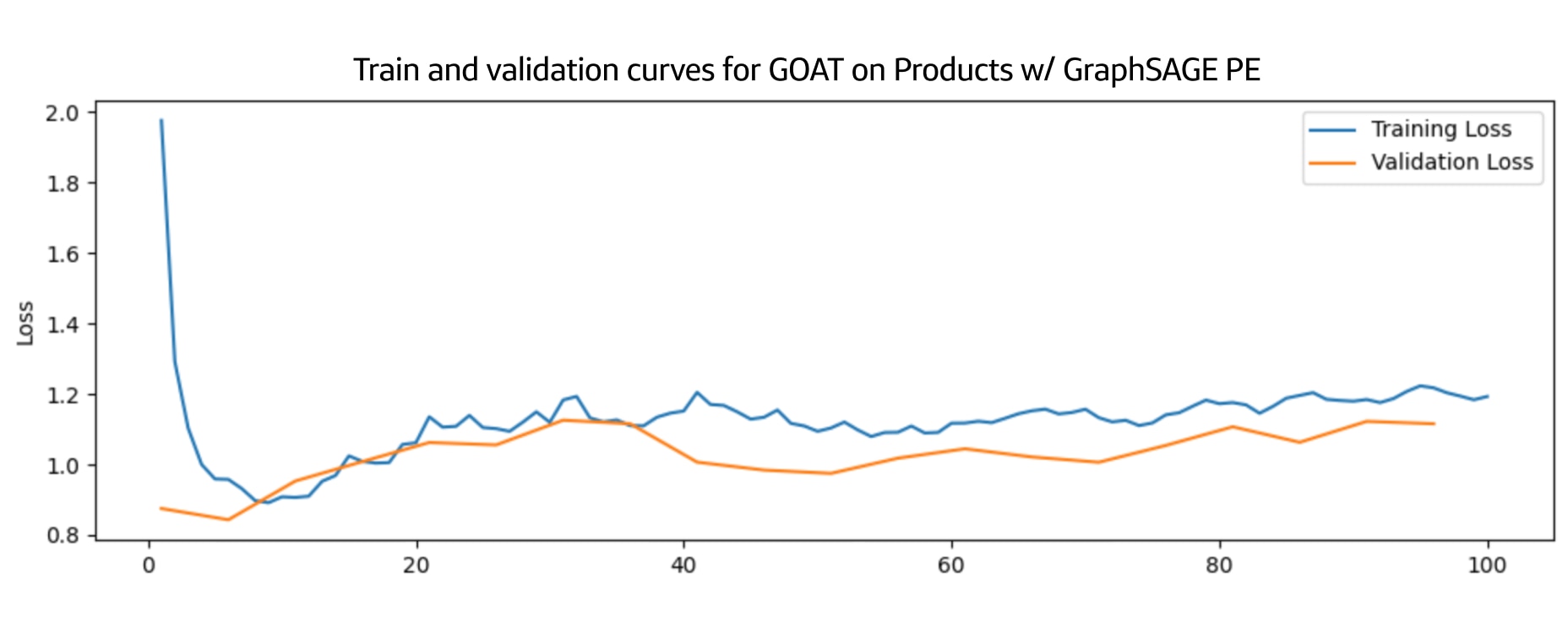
Results of the GOAT model training with the products dataset for GraphSAGE
NAGPhormer model, ArXiv and products dataset
We examined NAGPhormer as an additional model to see if the results for GOAT could be seen on other graph transformers. The results for NAGPhormer with and without positional encodings are strikingly similar. This trend held across the two datasets. We saw the same overall shape in most of the accuracy and loss curves with even fewer variations than GOAT. For some positional encodings we noted initial training loss being slightly lower than that of the noPE baseline; however we see performance in later epochs tends to be very similar as they converge to a similar loss value, seemingly outweighing the initial benefit of using positional encodings. An example is shown below with loss curves for three positional encodings and the baseline on the same chart.
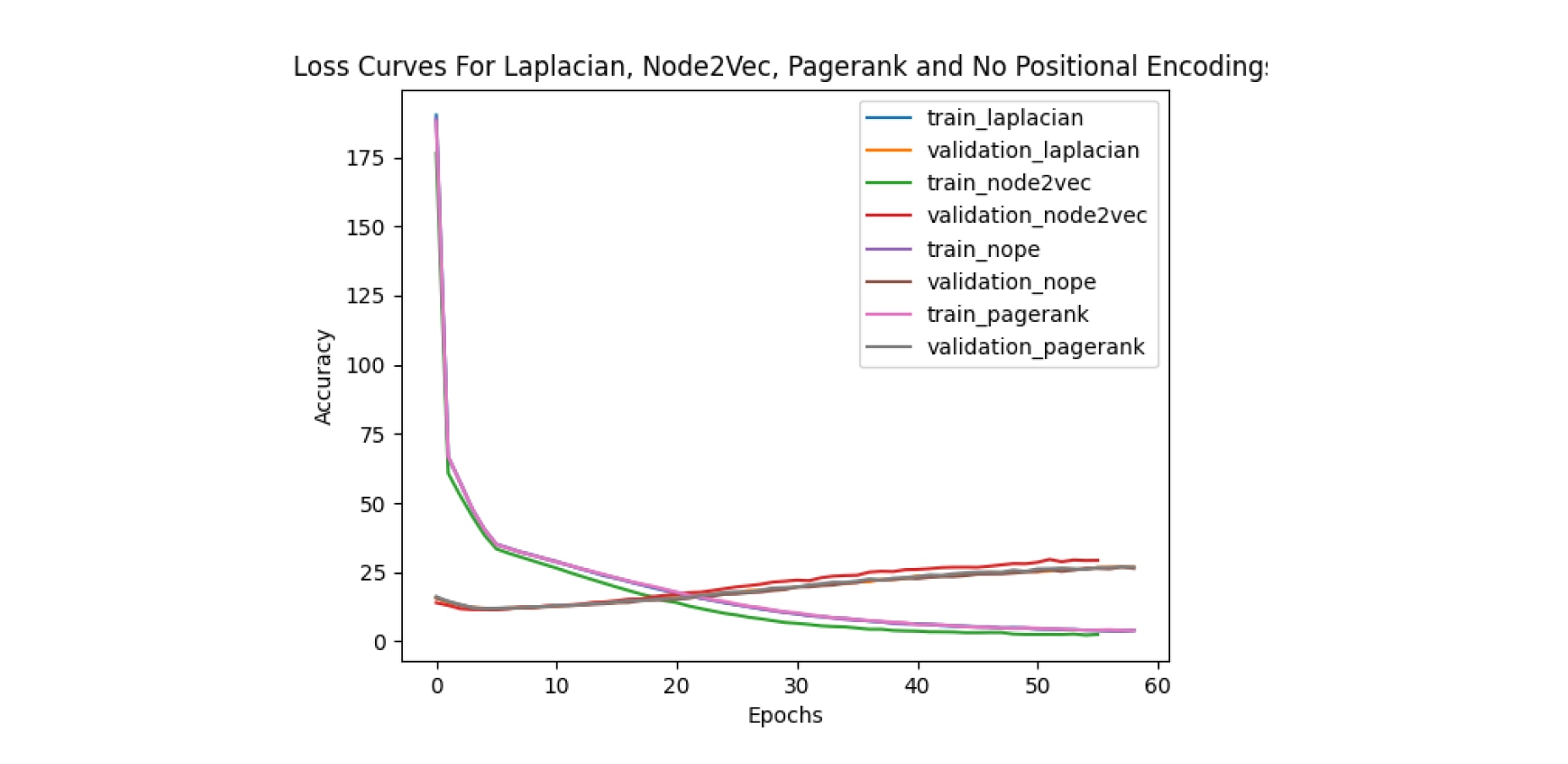
Results of NAGPhormer model training without positional encodings for PageRank
Accuracy comparison across different positional encodings
A summary of our final test metrics is presented below. The highlighted values represent the top accuracy score in each row, and the negative number below represents the difference between the value of that specific test and the top accuracy in the row. As we can see, for most of the positional encodings, the effects on accuracy are very small, typically less than 0.05 with PageRank on ArXiv standing out as clearly worse, performing almost 0.2 less than the best accuracy of SAGE. We also note that for Random Walk Positional Encodings (RWPE) results could not be calculated for the Products dataset since RWPE could not scale to process OGBN Products.
| Best Epoch Test Accuracy | ||||||
| NoPe | Node2Vec | SAGE | Laplacian | PageRank | RWPE | |
| GOAT Arxiv |
0.717 |
0.720 |
0.722 |
0.718 |
0.524 |
0.717 |
| GOAT Products |
0.786 |
0.764 |
0.793 |
0.804 |
0.815 |
N/A |
| NAG Arxiv |
0.639 |
0.655 |
0.644 |
0.633 |
0.629 |
0.0636 |
| NAG Products | 0.755 (-0.0) |
0.748 (-0.007) |
0.745 (-0.005) |
0.751 (-0.004) |
0.754 (-0.001) |
N/A |
Interestingly, from our observations and test results gathered from the various positional encoding techniques and datasets, the positional encodings we evaluated did not produce significant differences for graph transformers. We observed the best accuracy metrics for all positional encodings across 2 datasets, and applied on 2 different graph transformers. From each experiment run, many test accuracy metrics we obtained from experiment runs using positional encodings had similar results to the baseline, noPE.
In addition to the minimal observed benefits positional encodings offered to our transformers, we observed that model training took a long time. For the major retailer products dataset, for example, we observed that model training with GOAT and NAGphormer took several days. Considering this time cost and minimal benefit to key metrics, we ask whether positional encodings are a worthy investment for graph transformer architectures. More studies should be run to verify these findings.
Future research on the effectiveness of positional encodings on graph transformers
Overall, our findings only scratch the surface of investigating how effective positional encodings are in Graph Transformers. Going forward, we propose several potential avenues for future research:
-
Explore a wider variety of datasets and positional encodings to corroborate the findings of our experiments.
-
Perform additional tests/runs to determine which results are statistically significant and which are due to variance.
-
What traits in encoding techniques are best for each different transformer model? How can we devise a methodical approach to selection positional encoding techniques?
-
How do newer inductive methods to generate positional encodings compare to more traditional transductive techniques.
-
Graph structure – how does variability in graph structure (i.e. density, size, etc.) affect performance of PE techniques for Graph transformers?
Explore Capital One's AI research efforts and career opportunities
New to tech at Capital One?
-
See how we're advancing the state-of-the-art in AI for financial services.
-
Learn how we’re delivering value to millions of customers with proprietary AI solutions.
-
Explore AI jobs and join our world-class team in accelerating AI research to change banking for good.
---
This blog was authored by the 2024 UMD Tech Incubator intern cohort
Capital One created two campus Tech Incubators at University of Maryland (UMD) and University of Illinois (UIUC). These physical spaces are home to the Tech Incubator internship. Interns are hired from these universities year-around to work on emerging AI and ML capabilities within the company. This blog was written by Abishay Reddy, Anoushka Arora, Vignesh Rangarajan and James Peng, part of the summer 2024 intern cohort.

