New Machine Learning features added to rubicon-ml
By Ryan Soley, Shania Mahmud and Srilatha Ranganathan
rubicon-ml is an open source machine learning solution providing user-friendly logging during model training and execution and we’ve recently added some news features. If you’re new to rubicon-ml, it captures and stores information like parameters and outcomes in a repeatable and shareable manner while relying on tried and tested open source libraries to do all the heavy lifting. During model experimentation and training, rubicon-ml leverages fsspec to facilitate writing for multiple backend filesystems which is used by other popular libraries like Dask and Pandas. This use in other well known libraries provides confidence that the tools rubicon-ml relies on are being actively maintained by the open source community and are aligned to the industry's latest standards.
The latest 0.3.x line of releases have enhanced rubicon-ml's ability to interact with other open source projects throughout the model development and review lifecycle. A typical model development workflow utilizing rubicon-ml may look something like this:
- Experiment and train a model (including grid search, feature selection, etc.) while logging inputs and outputs;
- Visualize said experimentation with the rubicon-ml widgets and dashboard; and
- Share experiments with collaborators and/or reviewers
To complete the aforementioned tasks, rubicon-ml leverages existing open source tooling:
- Scikit-learn for model training
- Dash and Plotly for visualizations
- Intake for sharing experimental results
In a number of releases since version 0.3.0, we've enhanced rubicon-ml's capabilities that leverage each of these three libraries to provide a better logging and sharing experience.
Using rubicon-ml with Scikit-learn for Model Training
Scikit-learn is an open source machine learning library that provides a standardized Python API, familiar to the DS community and model developers with its specification for estimators and pipelines. Classes that fit this estimator and pipeline API specification can leverage any of Scikit-learn’s meta-estimators to perform feature selection and hyperparameter tuning. The toolkit makes machine learning easy and standardized with simple, reusable, and reliable components for modeling.
rubicon-ml’s Scikit-learn integration allows users to leverage Scikit-learn while logging import information for model development such as parameters and metrics using a drop-in replacement for Scikit-learn’s Pipeline class. When a rubicon-ml enabled Scikit-learn pipeline is fit, rubicon-ml will automatically log all of the pipeline’s input parameters to an experiment, rather than having the user explicitly log each value. Furthermore, it also allows developers to assign custom loggers to specific estimators in the pipeline and define custom logic for logging an estimator’s attributes.

rubicon-ml offers a drop-in replacement for the existing Scikit-learn Pipeline class
The newest installment of rubicon-ml enables simpler instantiation and creation of pipelines. rubicon-ml now supports the creation of Scikit-learn pipelines using make_pipeline. This feature eliminates the need for consumers to name estimators and associate the name with a custom logger. Now, creating pipelines with Rubicon is as simple as calling make_pipeline with estimator-logger pairs. Additionally, Scikit learn pipelines can now be sliced with rubicon-ml, giving model developers the ability to make a copy of a pipeline with only the subset of estimators needed.
Improvements to model scoring have also been made within the Scikit-learn integration. A single pipeline can be scored against different datasets multiple times and rubicon-ml will create a new experiment with the score of each dataset. rubicon-ml automatically supports the logging of scores from the pipeline’s score and score_samples methods to ensure all outputs can be captured.
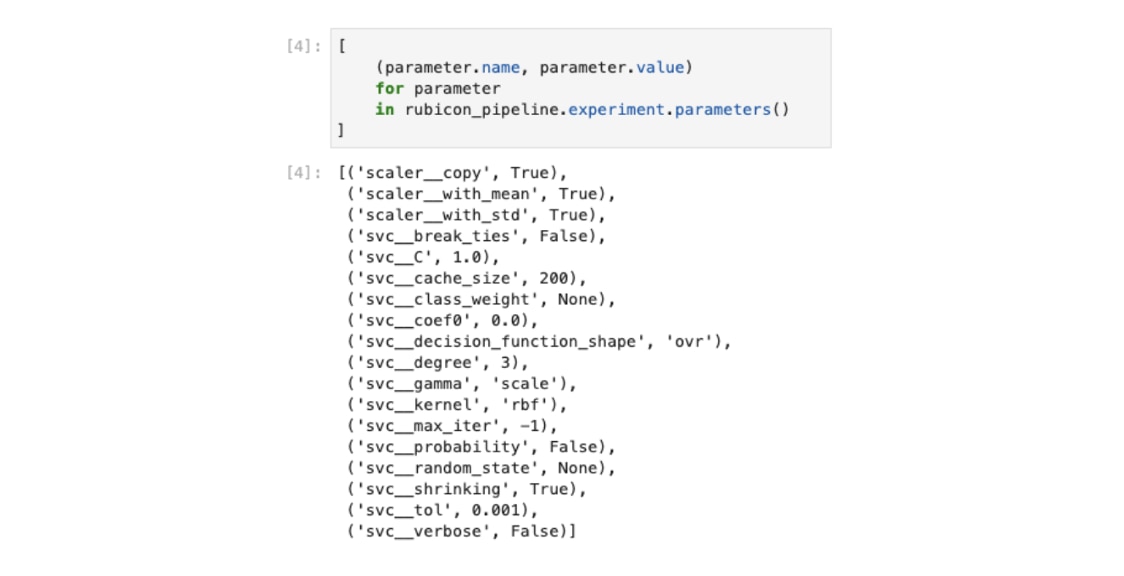
After fitting a rubicon-ml enabled pipeline, we can view each of the logged input parameters
Using rubicon-ml with Dash and Plotly to Visualize Experiments
As a model developer, analyzing the results of experiments with many different features and hyperparameters can be overwhelming. Models with large feature spaces and multiple hyperparameters to tune could easily result in thousands of experiments.
From the inception of rubicon-ml, there has always been a UI component to aid in this analysis. However, from our collaborations with multiple model developers we have found that most modeling problems are best visualized in many different ways. When we first reimagined rubicon-ml as a lightweight Python library (it used to be a hosted, centralized AWS service), we added all the visualizations to a single monolithic dashboard. This resulted in the UI becoming overwhelming not only to users who generally only cared about one part of it, but also to developers from a maintenance perspective.
So, in version 0.3.0, we redesigned rubicon-ml's visualizations to be more customizable and composable using Dash and Plotly. Now, instead of a single dashboard, rubicon-ml's visualizations are a suite of widgets that each have their own individual use case. These visualizations are built on top of Dash and Plotly, giving users the capability to run visualizations locally or host them in a variety of ways offered by Dash.
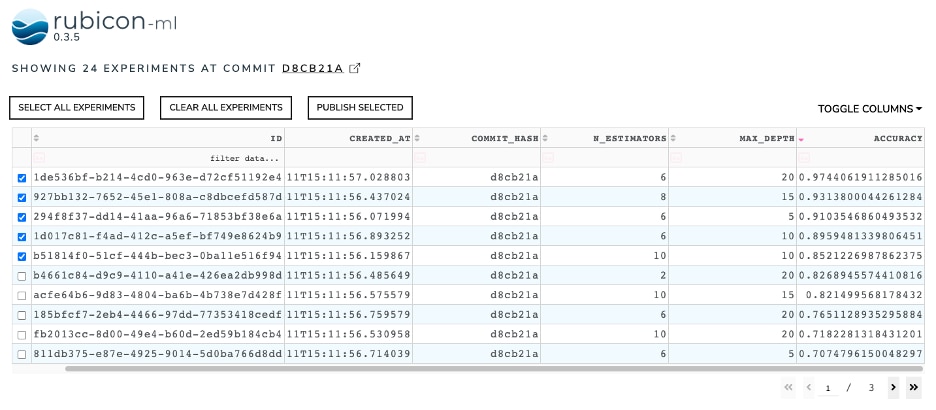
The widgets have a shared API in the rubicon-ml codebase, making it easy for collaborators and contributors to add their own widgets to the suite as the need arises. This means that there is no burden of rewriting any boilerplate code when developing a new widget. Developers can focus on novel functionality for their use case and only that!
The shared API also enables rubicon-ml to offer a new dashboard where users can pick and choose which visualization widgets to display. The experiment table shown above can even be used to control the selection of experiments that are shown in the other widgets on the dashboard.

Using rubicon-ml with Intake to Share Experiments
Now that we have experimented with Scikit-learn and visualized our results with Plotly and Dash - how do we share these results? That's where Intake comes in!
Intake is a library with a stated goal to "take the pain out of data access and distribution." Generally, Intake is used to provide a singular interface for disparate data sources in data science projects. For example, a model developer may have some data in S3 and some in a database somewhere. Intake is capable of exposing a single loading interface to read data from those separate places into a unified in-memory representation.
rubicon-ml leverages these capabilities to generate catalogs that can reference rubicon-ml experimental results in many places. If a model developer and their coworker are logging experiments to two (or more) different S3 buckets, they can use Intake to generate a catalog capable of loading projects from both buckets into a unified in-memory representation. rubicon-ml does not handle any data access on its own - if all collaborators have access to the underlying backend the experiments are logged to, sharing them is enabled by default.
Sharing results and collaborating with others to draw better conclusions is a huge part of the experimentation phase. Sometimes these collaborators can be as technical as the model developers, or they could be analysts from a different domain. Another goal of rubicon-ml's Intake integration is to make sharing experiments easy regardless of a consumer's technical skill level.
Intake catalogs can be read with a single call to the Intake library and return fully operational rubicon-ml experiment objects in-memory in your Python session. In the future, we plan on exposing this capability via a simple CLI so users don't even need to launch a Python interpreter. Future plans also include the ability to directly launch the visualizations detailed above from catalog files. This will make it simple for anyone to get a look at exactly what the model developers saw when they drew their conclusions.
Summary
As an open source machine learning solution, rubicon-ml allows model developers to easily experiment and log model metadata, analyze experiments with a suite of visualization widgets, and collaborate on experiments with others.
As rubicon-ml continues to evolve, stay tuned for updates to these integrations as well as new integrations with the next best Python machine learning libraries. If you use a tool that could be enhanced with automatic rubicon-ml logging, let us know by checking out our GitHub repo and opening an issue. Don't forget to stay tuned for our latest updates by making sure to star and watch on GitHub!



