Synthetic data matters for machine learning innovation
Data is the fundamental resource whose refinement enables some of today’s most advanced, real-time technology applications. At Capital One, quality data is key to powering machine learning models that create services to enhance protection of our customers, help them better manage their spending, and make banking more personalized, simple, and easy, including: credit card rewards, fraud protection, auto financing and shopping, and virtual card numbers, to name a few. To deliver these intelligent, contextually relevant experiences driven by AI and machine learning, we need to ensure responsible, well-managed access to the right kind of data.
Data access is regulated across many industries, and rightly so. The financial services industry, for example, has rigorous processes to protect private information. Such regulation can make accessing data for machine learning environments an interesting and complex challenge to solve both from a business application and from an academic research lens.
For example, what if a machine learning engineer in a bank wants to develop a new tool for fraud detection by using historical transaction data? Before the engineer can access the data, several steps must first be taken, including: defining the intent of the project, explaining how the data may be used, identifying the specific subset of data needed while ensuring that any data not immediately relevant to the project is not used; and various approval processes from there. Because of the iterative and explorative nature of research and development, this process might take place multiple times.
Apart from developing new business applications, many machine learning teams in regulated industries, including our team at Capital One, advance and contribute research to the ML community. Often, this research is done in collaboration with academic experts, who are not by law able to access real-world data. This all presents a unique challenge: how can AI/ML researchers in regulated industries advance innovation while ensuring data privacy is maintained? The answer could be in synthetic data.
Synthetic data is essentially a proxy for real data that can be used to achieve a desired machine learning modeling goal while avoiding the risk of using sensitive, real-world data. Synthetic has the ability to:
- Allow fast internal data sharing for the purpose of analytical tools research. It enables team members to test their hypothesis quickly and safely, and determine whether or not to pursue the current path or change course.
- Prevent real data from being circulated internally more than strictly necessary, mitigating privacy concerns or errors.
- Allow data-supported discussion on various business solutions with the larger industry and academic communities.
- Create safe spaces to explore what-if scenarios and conduct research that aims to prevent potential security flaws.
Ultimately, the final validation of an application would require using real data. However, instead of bringing the real data to the researcher, the researcher’s application and its testing process could be packaged and sent inside a super secure tech environment where the real data would be hosted. An automated process would test the application on real data and return only validation metrics to the researcher for further iterations: Figure 1.
Because Capital One is in a regulated industry, we're at the forefront of synthetic data use exploration. We believe, however, that synthetic data will become more important for everyone in the machine learning community. The most critical challenge will be creating useful synthetic data—data which can lead to valuable research results.
The potential benefits for innovation and development from synthetic data are clear: faster research cycles, enhanced data privacy, and greater collaboration across industry and academia.
Thanks to Isha Hameed for her contribution and coauthorship on this article.
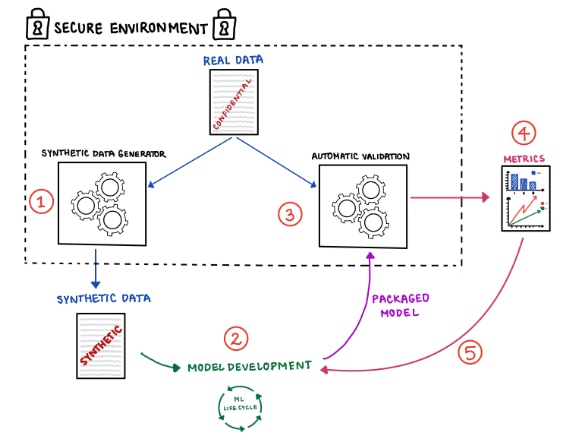
Figure 1: Using synthetic data in ML.


