Evaluating Data Quality for Machine Learning Models at Scale
Data monitoring using Data Profiler—an open source project from Capital One
Most software and machine learning related projects start with data. Loading, formatting, and validating data are therefore an important aspect to any engineer or data scientist’s role. “Garbage in, garbage out” as they say. With Data Profiler - an open source project from Capital One - you can easily evaluate and monitor data at scale.
As an applied researcher, I’m part of the team at Capital One that built Data Profiler to solve problems we encountered in our day to day machine learning work. Our team regularly utilizes a multitude of datasets to build various machine learning models. Often these models need to be refit, and failing to recognize a refit is necessary or orchestrating an unnecessary refit can dramatically impact our bottom line. We only want to refit our models when necessary, which means ensuring our training, validation, and test data is appropriately balanced prior to running our training model(s). And of course, in a large enterprise like Capital One, the intent is to do this at scale across any dataset which is utilized in a downstream model.
With that in mind, my team needed a tool to do three things particularly well:
- Load & format data from a file
- Calculate schema & statistics
- Compare profiles & track changes
While there were many tools in the market (notably tools such as pandas-profiling), none of them met our criteria. We needed to profile any data (structured or unstructured) without having to specify the file type (JSON, delimited, etc) or encoding and also have the ability to provide actionable insights in a scaled manner. Thus we ended up building the open source Data Profiler library ourselves.
- Load & format data from a file → DataProfiler.Data
- Calculate schema & statistics → DataProfiler.Profiler
- Compare profiles & track changes → DataProfiler.Report
In this blog I am going to explain how the DataProfiler library can help you evaluate data quality for machine learning models at scale by solving for our three requirements above.
Load & format data from a file with DataProfiler.Data
Often, prior to investigation(s), we do not know how the data is formatted. In order to create a standardized data pipeline, we needed an automated solution to load and format data. With that in mind, we built the Data Profiler’s Data class, which will automatically identify and load >99% of the data encountered. The end goal being a single command that can load any delimited, JSON, Parquet, AVRO or text file into a data structure compatible with pandas dataframe.

As an example of how complicated this can be, take the following example (this was my daily planning sheet from the start of 2020):

In order to load the file via Data Profiler, we needed the library to automatically identify:
- That it is a delimited file
- The type of delimiter -- “@”
- That the header starts on the second row
In a similarly complex situation, nested JSON objects often exist so there needs to be a way to easily load them into a standard format. Take the example below, a randomly created nested JSON:

For our purposes, the DataProfiler works well and can load and format >99% of the datasets encountered. Further, as the data is loaded into a data structure compatible with a pandas dataframe, we can use many standard functions such as sort or head.
Calculate schema & statistics with DataProfiler.Profiler
Once the data is loaded into the Data class, the goal is to obtain a profile with as much detail as possible to make actionable insights. In terms of the DataProfiler library, this includes both global (whole dataset) and column / row or key level statistics.
We want to be able to collect profiles simultaneously across multiple files then merge the profiles and / or save profiles for later analysis or time-series tracking. With that in mind, we had several constraints on Data Profiler:
- All statistics must be calculated in one pass: O(n).
- Calculations should be able to use a subsample of the dataset.
- Any calculations need to be up-datable in streaming / batch.
- Profiles need to be able to be merged (assuming the same schema).
- Profiles need to be able to be saved / loaded.
In terms of the API to generate a profile, it’s a single command:

In terms of the global and column / row level statistics gained, the list is quite large. Needless to say, Data Profiler calculates a multitude of statistics & attributes:
- Number of nulls in a column
- Number of null rows
- Predicts the entity of a column (address, phone number, name, etc)
- The distributions (histograms, quantiles, etc)
- Correlation between columns
- Determines if a column / key has a categorical values
- And many more..
The full list of statistics obtained can be found on the Data Profiler GitHub repository as it is always expanding.
Once a profile is obtained from the Profiler class, the profiles can be merged, assuming the schema is consistent between the data files.
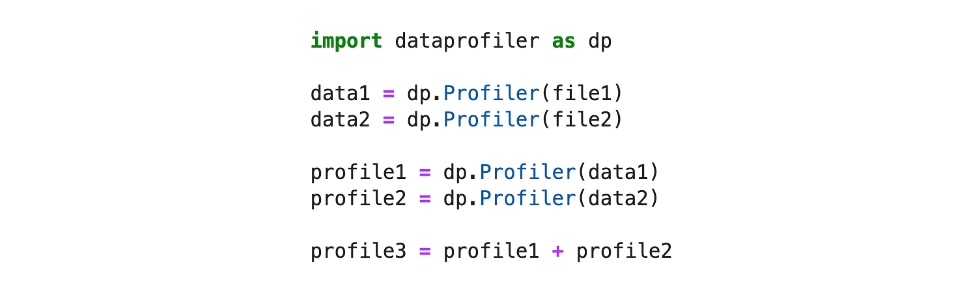
This enables multiple Profiles to be processed simultaneously then merged into one aggregate profile. The ability to merge Profiles is one of the key differentiators of the Data Profiler as it maximizes resources and allows parallelization. Profiles can also be saved to disk and later retrieved for analysis or even updating with new datasets.

This particular Data Profiler feature is extremely useful for doing analysis into model or data drift. Storing data profiles with models enables an evaluation into potential weaknesses within the models.
Finally, to easily examine the profiles, we created a report function.

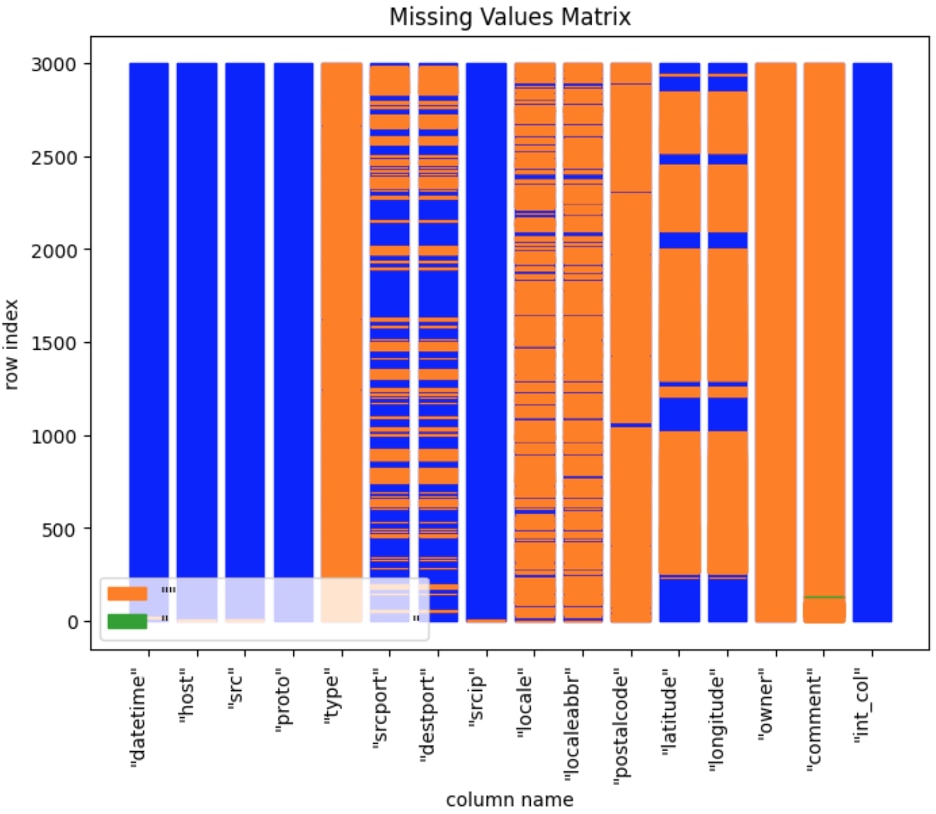
It is even possible to graph part of the report, for instance the nulls in the database:

Compare profiles & track changes with DataProfiler.Report
Finally, we get to the point where we can compare profiles (i.e. datasets). To easily compare two datasets, Data Profiler comes with a “diff” function in the Profile class. It's important to know if the training and validation datasets match the test dataset or live data streaming through the system. If the data profiles don’t match, it could indicate reduced model accuracy / performance.
The code itself is relatively simple. Imagine we want to load a dataset, split into the training & testing dataset, then compare the datasets to see if there are any major differences:

The report that is generated will effectively show the differences between values, with any matching values being labeled as “unchanged.” In the example below, there are an additional 63 duplicate rows in the profiler_training dataset vs the profiler_testing dataset (everything else is unchanged):

In the individual columns you can see there are more differences, but generally the various statistical components are very similar.
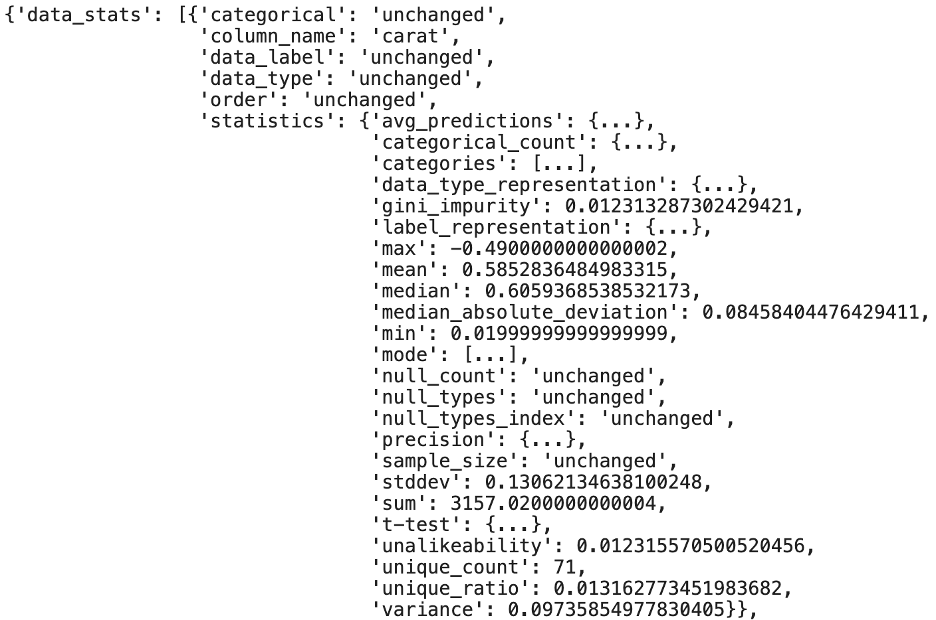
At a quick glance, there are no large differences between the datasets, so the model(s) should be fairly stable between the training and testing datasets.
Going forward, the training dataset profile can then be saved with the trained model and new profiles can be generated on the fly utilizing samples from live datasets. If the live datasets deviate outside the expected data profile (say a column starts becoming nulls), then we can issue a warning prior to potential model failures impacting business decisions.
Start Using the Data Profiler Library
Whether you're a data scientist or a software, data, or machine learning engineer, we built the Data Profiler library to help simplify many of your daily tasks. It has dramatically improved our team’s ability to monitor data sets and enables us to quickly do analysis or start building machine learning models within minutes. We believe it can help many of your use cases as well.
For those interested in getting started with the Data Profiler library, install via:
pip install DataProfiler[full] --userIf you have any issues or questions, feel free to check out the Data Profiler GitHub repository for more information on the project, including details on how to contribute to Data Profiler. Or you can read our previous articles here - Data Profiler - An Open Source Solution to Explain Your Data and Detecting Sensitive Information in Data with Data Profiler.


