Detecting sensitive information in data with Data Profiler
Simplifying detection with just a few lines of code using Data Profiler—an open source project from Capital One
Companies rely on their customer data to improve their business quality and customer service. This necessitates the requirement of protecting their private customer information such as Personally Identifiable Information (PII) and Non-Public Personal Information (NPI). This information may include, but is not limited to, customer names, physical addresses, IP addresses, bank account numbers, and credit card numbers. This sensitive information exists in many data sources under both unstructured (phone transcripts from customers) and structured (tabular transaction data) datasets. In order to detect sensitive information from these sources, my team at Capital One has developed a quick-and-easy-to-use open source library, Data Profiler, that helps read and identify sensitive information from different file types.
Let’s walk through several examples of how we use the Data Profiler library on some public datasets.
Example of prediction on structured data using Data Profiler
First, let us look at a public, tabular dataset on internet traffic using the data reader class of the Data Profiler.
import dataprofiler as dp
import json
import pandas as pd
data = dp.Data("data/structured/aws_honeypot_marx_geo.csv")
df_data = data.data
df_data.head()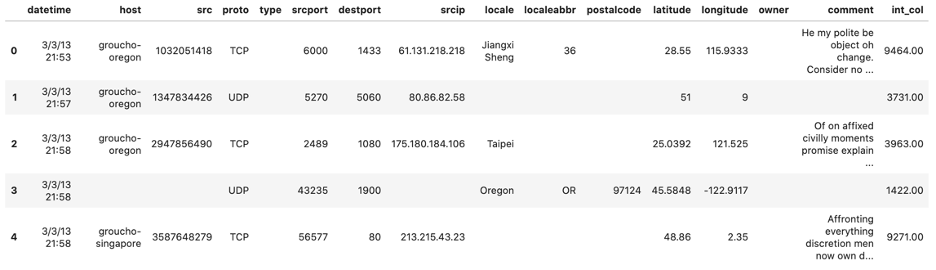
The returned data is a Pandas dataframe, which contains sixteen columns, each of which has a different data label. To predict these data labels, we will use the data labeler from Data Profiler.
|
Note that, besides data labeler, Data Profiler also provides the identification of data types and data statistics for each column. In the scope of this post, we disable those options and keep only the data label functionality. |
# set option to run only data labeler
profile_options = dp.ProfilerOptions()
profile_options.set({"text.is_enabled": False,
"int.is_enabled": False,
"float.is_enabled": False,
"order.is_enabled": False,
"category.is_enabled": False,
"datetime.is_enabled": False,})
profile = dp.Profiler(data, profiler_options=profile_options)That’s it! After running the Data Profiler, we get the results in profile.report. By default, the reported results contain lots of detailed information about the whole dataset. For this example, we only need the predicted label for each column. The below script shows results at the column level.
# get the prediction from data profiler
results = profile.report()
columns, predictions = [], []
for col in results['data_stats']:
columns.append(col)
predictions.append(results['data_stats'][col]['data_label'])
df_results = pd.DataFrame({'Column': columns, 'Prediction': predictions})
print(df_results)
The results show that the Data Profiler is able to detect sensitive information such as datetime, ipv4, or address. It predicts None for the empty column ‘owner’ and BACKGROUND for columns with miscellaneous information. With several lines of code, we are able to identify some sensitive information in our dataset, which can subsequently be used to help companies protect their data efficiently by applying different tokenization techniques for different types of sensitive information.
Example of prediction on unstructured data using Data Profiler
Besides structured data, Data Profiler can also detect sensitive information on unstructured data. Here we’ll use a sample of spam email from an Enron email dataset for this demo. As above, we start investigating the content of the given email sample.
# load data
data = dp.Data("data/emails/enron-sample")
print(data.data[0])|
Message-ID: <11111111.1111111111111.JavaMail.evans@thyme> Date: Fri, 10 Aug 2005 11:31:37 -0700 (PDT) From: w..smith@company.com To: john.smith@company.com Subject: RE: ABC Mime-Version: 1.0 Content-Type: text/plain; charset=us-ascii Content-Transfer-Encoding: 7bit X-From: Smith, Mary W. </O=ENRON/OU=NA/CN=RECIPIENTS/CN=SSMITH> X-To: Smith, John </O=ENRON/OU=NA/CN=RECIPIENTS/CN=JSMITH> X-cc: X-bcc: X-Folder: \SSMITH (Non-Privileged)\Sent Items X-Origin: Smith-S X-FileName: SSMITH (Non-Privileged).pst
All I ever saw was the e-mail from the office. Mary
-----Original Message----- From: Smith, John Sent: Friday, August 10, 2005 13:07 PM To: Smith, Mary W. Subject: ABC Have you heard any more regarding the ABC sale? I guess that means that it's no big deal here, but you think they would have send something. John Smith 123-456-7890 |
Here we have an email with a header, the main content, the original message, and a signature part at the end. With this unstructured text, we directly use the data labeler to predict the location of sensitive information therein.
data_labeler = dp.DataLabeler(labeler_type='unstructured')
predictions = data_labeler.predict(data)
print(predictions['pred'])
[array([ 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
20., 20., 21., 21., 6., 6., 6., 6., 7., 7., 7., 7., 7.,
...
15., 15., 15., 15., 15., 1., 16., 16., 16., 16., 16., 16., 16.,
16., 16., 16., 16., 16., 1.])]|
Note that the unstructured type of the data labeler is used with text. By default, the data labeler predicts the results at the character level for unstructured text. It also provides alternative representations as chosen by users for better interpretability. For example, the prediction results can be at the word level following the standard NER (Named Entity Recognition) format, e.g., utilized by spaCy. All we need to do is to add several options to the postprocessor of the data labeler. |
# convert prediction to word format and ner format
# Set the output to the NER format (start position, end position, label)
data_labeler.set_params(
{'postprocessor': {'output_format':'ner', 'use_word_level_argmax':True}}
)
predictions = data_labeler.predict(data)
# display results
for pred in predictions['pred'][0]:
print('{}: {}'.format(data.data[0][pred[0]: pred[1]], pred[2]))
print('--------------------------------------------------------')|
evans@thyme>: EMAIL_ADDRESS -------------------------------------------------------- Fri, 10: DATE -------------------------------------------------------- Aug 2005 11: DATETIME -------------------------------------------------------- smith@company.com: EMAIL_ADDRESS -------------------------------------------------------- john.smith@company.com: EMAIL_ADDRESS -------------------------------------------------------- 7bit: QUANTITY -------------------------------------------------------- Smith, Mary W: PERSON -------------------------------------------------------- </O=ENRON/OU=NA/CN=RECIPIENTS/CN=SSMITH>: HASH_OR_KEY -------------------------------------------------------- Smith, John: PERSON -------------------------------------------------------- </O=ENRON/OU=NA/CN=RECIPIENTS/CN=JSMITH>: HASH_OR_KEY -------------------------------------------------------- -----Original: QUANTITY -------------------------------------------------------- Smith, John: PERSON -------------------------------------------------------- Friday, August 10, 2005 13: DATETIME -------------------------------------------------------- Smith, Mary W.: PERSON -------------------------------------------------------- John Smith: PERSON -------------------------------------------------------- 123-456-7890: PHONE_NUMBER ------------------------------------------------------- |
Here Data Profiler identifies sensitive information such as datetime, email address, person names, and phone number within this random email.
Conclusion
The Data Profiler open source library is a great solution for companies looking to quickly detect sensitive information in their data lakes. It can be used to scan through both structured and unstructured data with different file types. We encourage readers to visit Data Profiler on Github for more information on the project and details on how to contribute to Data Profiler.
References
[1] Github repo: https://github.com/capitalone/DataProfiler
[2] Sensitive Data Detection with High-throughput Neural Network Models for Financial Institutions: https://arxiv.org/pdf/2012.09597.pdf


