Continuous Chaos — Introducing Chaos Engineering into DevOps Practices
A guest post by Sathiya Shunmugasundaram
Traditional testing approaches can’t predict all failure modes; Chaos Engineering is a discipline to simulate these failures and build better applications. It’s about introducing controlled disruptions into a distributed system, carefully studying the behavior, identifying the weak areas, and improving resiliency with automation. Adding continuous chaos to DevOps culture helps us build better anti-fragile applications.

So, what are the various phases of Chaos Engineering? Let’s describe them.
Application Assessment for Readiness
Before an org can start running Chaos Experiments on an application, you need to assess it for readiness. This means going over the following:
- The Application Architecture must be reviewed in depth to identify various failure points, dependencies, customer impact, and recovery procedures.
- Identify potential failure points which may not be optimal for running chaos testing.
- Certify Chaos Testing Readiness for targeted components/services.
Once you’ve determined that you’re ready to test, it’s time to define some parameters.
Define Steady-State Behaviors and Form Hypotheses
Steady-State Behavior
First, define the steady-state behavior of the application. This refers to the normal operation of the application. Keep in mind, SLAs must be taken into account for the steady-state.
To define the steady-state, you should use both technical and business metrics. Some samples are as below:
Technical Metrics
- Latency
- Number of errors thrown over a period
- Results from health end endpoint
- Average CPU
Business Metrics
- Number of logins per minute during peak
- Number of failed logins per minute
- Number of declined transactions per second
Form Hypotheses
Once you’ve define the steady-state behavior, the next goal is to form some hypothesis of what you expect from the Chaos Experiment.
Some hypotheses may include, but are not limited to:
- The Application Health Check endpoint will not be impacted throughout the experiment.
- When a random virtual machine is terminated, our failures are negligible at < 10 failed logins per 10,000 logins.
- When the Database fails over, the application will continue to function normally but will provide a friendly message for certain transactions to retry after few minutes.
- When testing geographical failure, the application will be down for five minutes, but a static site will serve some basic information.
Define the Chaos Experiments You’ll Be Running
Unlike a traditional testing approach, with Chaos Experiments we’re studying expected outcomes rather than predicting exact behaviors. For example, when we terminate 33% of auto-scaling group instances to simulate an AZ failure, we expect that ASG will spin up new instances and the application will eventually be at full capacity. But how many in-flight transactions will be affected? Actual customer impact is something we could form a hypothesis for, but we will have to study the outcome to understand actual behavior and address gaps in the system.
Define your experiments according to the application architecture, keeping in mind known limitations. Note that these should be real-world events.
The following are sample experiments for a generic three tier application deployed in two regions. This list is not comprehensive and depends on the application tooling support and maturity, but it is a good starting point.
- Terminate random virtual server in a region.
- Subject entire fleet to high CPU/Memory within a region.
- Increase latency in one or more servers.
- Block access to a storage system.
- Failover a database to its secondary.
- Random killing of critical processes.
Once an application demonstrates resilience to these basic experiments, the experiments should be compounded to increase the intensity of the experiment. Some samples of what this could look like are below:
- Hog both CPU and memory in part of the fleet.
- Terminate virtual servers while database is failing over.
By varying these real-world events and continuing to study the behavior of the systems, we can address the gaps and revisit the steady-state. Then we can form new hypotheses and create a feedback loop until we exhaust our hypotheses. All while we continue to run tests to ensure that any change in the system didn’t invalidate the previous hypotheses.
Bring Chaos into Practice
Once Chaos Engineering objectives are set, it’s time to bring them to reality. The practice should be adopted incrementally from lower environments all the way to live production systems. The practice should mature over time and eventually become part of standard development with developers improving systems until they’re not even aware of chaos injection schedule, instead relying on resilient systems to handle it all the time.
Run Experiments in Pre-Production Environments
Once the approach is solidified, we can get our feet wet on the testing approach and tooling in the QA environment. Here we do functional testing validations, mainly to validate the business metrics. Note — since the system is not under load, many technical metrics may not be visible at this point in time.
Once the functional validation is finished, we can move on to other advanced testing strategies which include — but are not limited to — load testing, performance testing, and endurance testing. These testing approaches expose vulnerabilities in the system that are visible only under certain conditions like a high load. Note — at any point in time, the testing must support stopping the experiment to mitigate further risk when things do not go as we expected.
Throughout the pre-production testing, the results are fed back into the application design/architecture and repeated until all the hypotheses are validated against steady-state behavior and we are ready to move on to production.
Game-Day for the Production Environment
Planning a “game-day” makes sure that the right personnel is available to run tests, handle failures, and discuss the outcome in real-time when you move testing to production. Here are some possible steps to preparing for game-day. These will vary by organization and the property being tested, you will need to do research to determine the right steps for your needs:
- Pre-production steady-state behaviors, hypotheses, and the Chaos Experiments are reviewed for production applicability and evaluated against the risk of customer impact.
- Experiments which are beyond the acceptable scope of impact will be deferred until the system is re-architected to handle them.
- Schedule the game-day when the application experts, the Chaos Engineering experts, and other stakeholders can gather and review the plan.
- Tests are run in an incremental fashion while monitoring the situation, validating that the system is functioning as expected, and moving on to next experiment when completed.
Additionally, the following should be taken into account:
- Ideally, failures must be handled automatically, and the system must be self-healing as failures occur.
- The experiment must stop immediately if the system deviates from normal behavior.
At the end of game-day, you should walk out with takeaways to address any gaps found in the system and the variance of results in pre-production vs. production systems. The issues found must be addressed, another game-day should be scheduled, and this should be repeated until you become confident that the system is resilient to the failure scenarios you are testing for.
Integrate Chaos Testing with CICD Pipeline
Once the Chaos Experiments are validated in the development-through-production cycle, it makes sense to integrate with your CICD. As part of the deployment pipeline, a Chaos Configuration File can be pushed to start disruptions in the specific environment. Some of the scenarios you can use are:
- Disrupt the virtual servers when a deployment is still being pushed.
- Orchestrate a “canary deployment” through the pipeline, induce failures in the new version of the microservice, and check behavior of system.
- Kick off a load test after deployment, terminate a few instances and validate that the system can consistently handle the load under reduced capacity.
By including Chaos Testing as part of the CICD pipeline, several hypotheses are continuously validated. For example, a deployment should always succeed even if some instances are not available during the deployment.
Enable Random Chaos in Production
At this stage, applications are expected to be self-healing and able to sustain all knownfailures. Applications must have monitoring infrastructure in place which can continually provide feedback about the steady-state behavior of the system and alert when deviating from the norm.
Once the Chaos Testing has passed the game-day and been continuously validated in a CICD pipeline, we are in a position to enable it in production. This should be done incrementally, but in a random fashion, without notifying the support teams. This has to be done carefully and the tooling must be mature enough to stop the testing without further impacts.
Generally, Chaos Testing will be initialized during random non-peak times. Over a period of time, the application should reach the maturity point where it can be tested at peak times.
Chaos Engineering Maturity
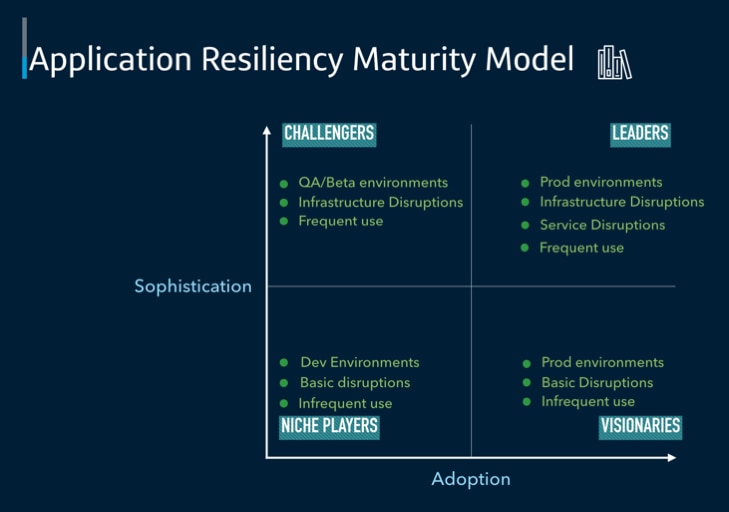
This diagram shows what Chaos Engineering maturity looks like.
The maturity model depicts how the applications can achieve the maturity by progressively adopting the practice from no chaos to being leaders in the space. The horizontal axis focuses on adoption, while the vertical axis focuses on the sophistication of the tooling involved.
Strong and resilient applications push the needle on both adoption and advanced tooling, evolving as leaders in the space. By making Chaos Engineering part of the DevOps culture, developers and stakeholders continually embrace failure as a way to prepare for and prevent it, resulting in stronger and more resilient applications.
To learn more about Sathiya’s views on DevOps and Chaos Engineering follow him on Medium or Twitter.

