Capturing & displaying data transformations with Spline
How this open source tool can help automatically track & display data lineage from Apache Spark applications

As a data engineer, I often see new teams or team members asked to support an existing data model where the documentation concerning the inputs, outputs, and movements of the data used is lacking. These inputs, outputs, and movements collectively comprise data lineage, which is the history of a set of data, including its origin, transformations, and movement over time.
Although data lineage can be defined manually, capturing data lineage manually--especially as an application’s logic changes over time--can be very time consuming and prone to human error. As a data engineer, it would be extremely beneficial to be able to capture data lineage as a normal part of an application’s flow, and to be able to display that data lineage in a format that is easily understood for documentation purposes. Fortunately, I work on a team at Capital One whose primary function is to support existing data models across several organizations and keep up-to-date with enterprise standards. We have found a great solution for our use case in Spline, an open source tool for automatically tracking and displaying data lineage from Apache Spark applications. Spline is maintained by ABSA OSS and you can read more at https://github.com/AbsaOSS.
In this blog I am going to cover:
- The benefits of defining, capturing, and displaying data lineage
- Generating data with PySpark
- Capturing data lineage with Spline
- Displaying data lineage with Spline
The benefits of defining, capturing, and displaying data lineage
Organizations interested in generating and analyzing data will often define data lineage as part of the development cycle of applications and pipelines for that purpose, even if informally. However, there are benefits to the additional steps of capturing and displaying data lineage, explained below.
Defining data lineage
Defining data lineage can be done prior to the development of an application or pipeline. This benefits the organization by:
- Enabling the ability to choose inputs based on the data they contain and their quality.
- Identifying all transformations that must occur and confirming their validity.
- Setting expectations for the format of the output and how the data can be used downstream.
Doing this work at design-time can save an organization from headaches during development, and will facilitate collaboration with upstream and downstream partners due to the clear definition of expectations.
Capturing data lineage
Capturing data lineage is important to ensure that no drift has occurred between the transformations that were defined in the previous step and the transformations actually performed by the application or pipeline. The data lineage captured at run-time can also provide more information than the data lineage captured at design-time, such as record count and partition-specific metadata.
Displaying data lineage
Displaying data lineage facilitates understanding of the data’s origins and movements by presenting the information in a visual format. This information can serve as documentation for the business logic of the application or pipeline.
Most importantly, for organizations in highly-regulated industries, data lineage may be required to meet regulatory requirements
Using Spline to capture and display data lineage
First, let’s start with the basics, including key Spline components and setting up your Spline server. Then we’ll run an example Spark job and show how the Spline UI works.
An introduction to Spline components
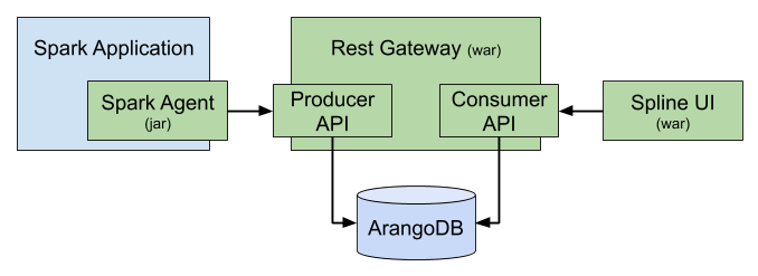
Diagram from Spline documentation at https://absaoss.github.io/spline.
In the above diagram, taken from the Spline documentation, the green boxes are Spline components. Let’s cover how each functions.
- Spline Spark Agent - The Spline Spark Agent is imported as a dependency for the Spark application. It will analyze the execution plans for the Spark jobs to capture the data lineage.
- Spline Rest Gateway - The Spline Rest Gateway receives the data lineage from the Spline Spark Agent and persists that information in ArangoDB.
- Spline UI - The Spline UI can be used to visualize all stored data lineage information.
Setting up your Spline Server
We are going to create our Spline Server by using the Docker images provided by ABSA OSS at https://github.com/AbsaOSS/spline-getting-started.
First, you should install Docker. Then, create and navigate to a sandbox directory to hold the files for this tutorial.
mkdir spline-sandbox
cd spline-sandboxNext, run the below to create all of the components from the diagram above:
curl -O https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/docker-compose.yml
curl -O https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/.env
docker-compose upNow, if you navigate to http://localhost:9090/ you will see that some data lineage is already present in your database. That is because docker-compose.yml includes a spline-spark-agent image that runs some examples for you.
Let’s create and run a new Spark job using PySpark.
Generating and capturing data lineage with PySpark and Spline
PySpark is a tool that allows developers to run Apache Spark jobs using Python.
Set up your PySpark environment by running the following:
# Install Python
brew install python
pip install 'pyspark==3.1.2'
# Create and navigate to a new directory
mkdir my-spark-job
cd my-spark-job
# Create input and output directories, and files
mkdir -p data/input
mkdir -p data/output
touch my_spark_job.py
touch data/input/user_favorites.csv
touch data/input/locations.csvNext, create a mock dataset that represents the favorite color and favorite city of some anonymous users. Add these contents to user_favorites.csv:
id,favorite_color,favorite_city
1,blue,anchorage
2,red,denver
3,orange,mesa
4,yellow,bakersfield
5,purple,portlandThen, create another mock dataset that contains locations. Add these contents to locations.csv:
id,city,state
1,bakersfield,california
2,portland,oregon
3,anchorage,alaska
4,mesa,arizona
5,denver,coloradoNow, let's create a Spark job called MySparkJob. In MySparkJob, we will use the above mock datasets to create a new dataset that contains a generated nickname for the anonymous users. Add the following contents to my_spark_job.py:
from pyspark.sql import SparkSession
# Create SparkSession
spark = SparkSession.builder.appName("MySparkJob").getOrCreate()
# Read user_favorites to DataFrame and create a temporary view
user_favorites = (
spark.read.option("header", "true")
.option("inferschema", "true")
.csv("data/input/user_favorites.csv")
)
user_favorites.createOrReplaceTempView("user_favorites")
# Read locations to DataFrame and create a temporary view
locations = (
spark.read.option("header", "true")
.option("inferschema", "true")
.csv("data/input/locations.csv")
)
locations.createOrReplaceTempView("locations")
# Join user_favorites and locations, and generate the nicknames
nicknames = spark.sql("""
SELECT
user_favorites.id,
CONCAT(
favorite_color,
' ',
state
) AS nickname
FROM user_favorites
JOIN locations
ON user_favorites.favorite_city = locations.city
""")
# Write output and print final DataFrame to console
nicknames.write.mode("overwrite").csv("data/output/nicknames")
nicknames.show(20, False)I have provided comments in the code that explain each step. Note that Spline only captures data lineage on write actions. You can read more about this behavior here.
Now, let’s run the Spark job and include the Spline Spark Agent as a dependency:
spark-submit \
--packages za.co.absa.spline.agent.spark:spark-3.1-spline-agent-bundle_2.12:0.6.1 \
--conf spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener \
--conf spark.spline.producer.url=http://localhost:8080/producer \
my_spark_job.pyIf you review the output from that command, you will see that our final DataFrame looks like:
+---+-----------------+
|id |nickname |
+---+-----------------+
|1 |blue alaska |
|2 |red colorado |
|3 |orange arizona |
|4 |yellow california|
|5 |purple oregon |
+---+-----------------+Now, let’s go back to http://localhost:9090/ and review the data lineage graphs generated by Spline.
Displaying data lineage with Spline

At the home page of the Spline UI, you will see a list of Execution Events. Search for the Spark job you just ran, which we called MySparkJob, and click on it.

You will arrive at an overview page, which shows the inputs, the Spark job, and the output. Click on the box with the arrow in the corner of the MySparkJob node.
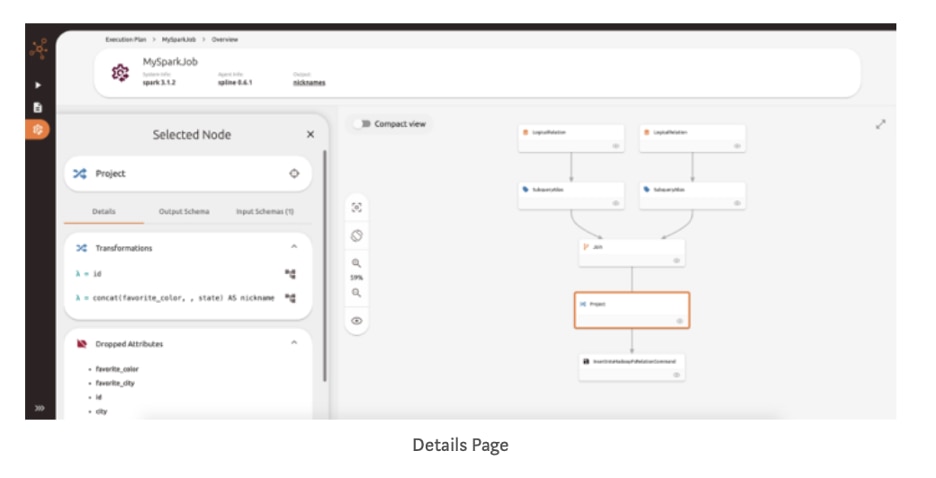
You will arrive at a details page for the Spark job. Here, if you click on a node, you will see the details for that particular operation. For example, if you click on the Project node at the bottom, you will see the transformation that occurred as a result of the SELECT operation that was performed.
If you go back to the home page, you can look through the details of the other example Spark jobs executed during the step where you built your Spline Server.
Resources
- Spline Blog: https://absaoss.github.io/spline/
- ABSA OSS GitHub Organization: https://github.com/AbsaOSS
- Spline - Getting Started: https://github.com/AbsaOSS/spline-getting-started
Conclusion
Now that you have seen Spline in action, you should be able to avoid the pitfalls of supporting an existing data model where the documentation concerning the inputs, outputs, and movements of the data used in the model is lacking.
You should also now be aware of how to:
- Generate data with PySpark.
- Capture data lineage with Spline.
- Display data lineage with Spline.
As with all open source projects, I encourage you to consider contributing to Spline. The Spline libraries are located in the ABSA OSS GitHub Organization at https://github.com/AbsaOSS, where you can also read their in-depth documentation.